This follows on from: Generative AI for Genealogy – Data vs. GEDCOM files
Where the Difficulty Actually Lives
People assume the hard part is “the AI bit.” No. The hard part is everything around the AI bit.
To get an LLM to answer a genealogy question, four things must happen:
- It must understand the question (which is harder than it sounds when humans ask things like “Who was that chap married to Auntie Jean’s cousin?”).
- It must parse the GEDCOM and model it correctly in memory.
- It must relate the question to the data without hallucinating a new great‑grandfather.
- It must output the answer in actual English, not “LLM‑ese.”
I already had item 2 sorted. But items 1, 3, and 4? That’s where the LLM comes in, waving its metaphorical arms and saying, “I’ve got this,” while I quietly whisper, “Please don’t make anything up.”
The Basic Flow (Or: How Not to Confuse the AI)
Architects love diagrams. I could have drawn a UML flowchart, but honestly, nobody deserves that. So here’s the gist:
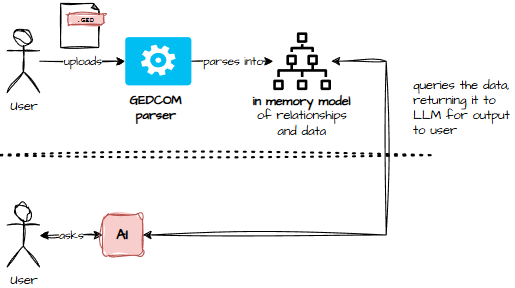
- The user uploads a GEDCOM.
- The parser stitches it into a relational model: parents, siblings, events, facts – the whole family circus.
- The AI then answers questions based on that model.
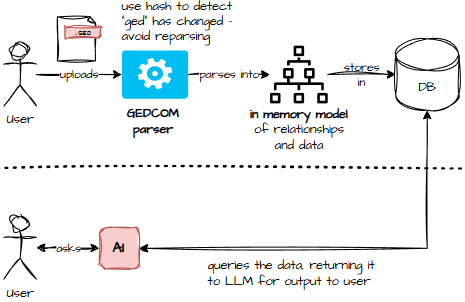
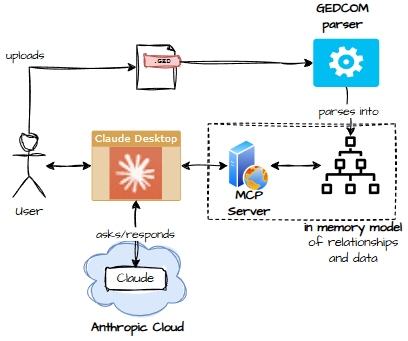
Two versions – depending on the endpoint, running locally can be in memory, cloud requires a shared persistent store for clustering to work.
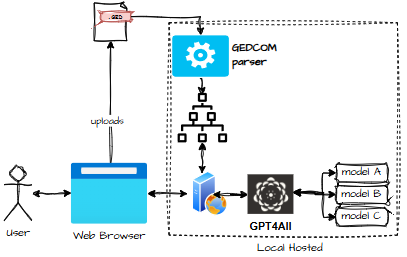
Architecture 1
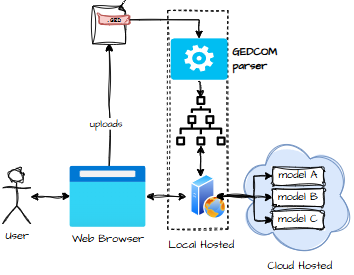
Architecture 2
Simple enough… until you realise the AI must always know who you’re talking about. Humans can say “my grandmother’s first husband,” and we nod knowingly. A model, however, needs a full dossier, three cross‑references, and a stiff drink.
Fat or Thin? (No, Not You – the App)
At some point, every architect must face the ancient question: Should this be a fat‑client app or a web app?
It’s a bit like choosing between tea and coffee. Both work. Both have consequences. Both can keep you awake at night.
Similarities
Regardless of the choice, the system needs:
- GEDCOM parsing
- An LLM to turn questions into actionable data
- An LLM to turn that data into human‑readable answers
Differences
This is where things get interesting.
A fat client can run everything locally even a local LLM like GPT4All. No cloud. No data leaving the user’s machine. No regulators breathing down my neck.
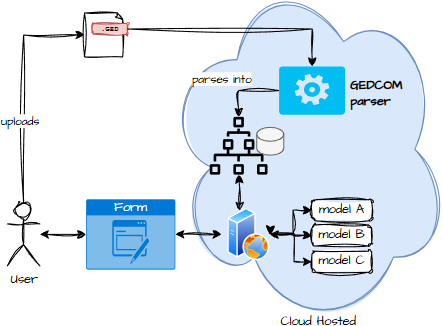
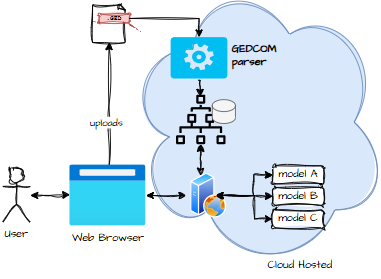
A thin client, on the other hand, means parsing in the cloud, storing data in the cloud, and answering questions in the cloud. Which is great… unless you remember that genealogy data includes living people. And regulators love living people.
Also, thin clients require clustering and sessions and other things that make architects sigh deeply.
Exploring the Options (A Tour of Possible Architectures)
Fat Client Options
- GPT4All locally Everything runs on the user’s machine. No cloud. No LLM costs. Downsides: deployment pain and performance that can best be described as “polite but slow.”
- Claude Desktop + local MCP server Claude does the thinking in the cloud; my MCP server provides the skills. Elegant, but it exposes living‑person data unless I jump through flaming hoops.
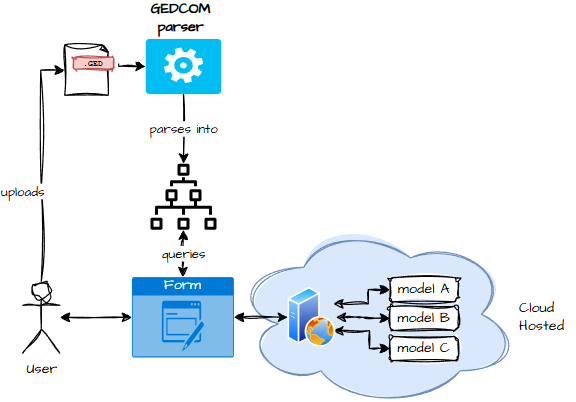
- Cloud LLM Local UI, cloud brain. Flexible, but requires sending data to the cloud.
- Cloud LLM + Cloud Data At this point, the “fat client” is basically a browser wearing a trench coat and pretending to be software.
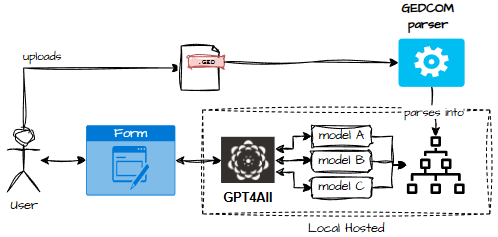
Thin Client Options
- Everything in the cloud Easy for users. Terrible for privacy.
- Locally hosted web server + local LLM A hybrid: browser UI, local processing. Surprisingly elegant.
- Local web server + cloud LLM Works well, but again, data must be sent to the cloud.
Decision Time
Eventually, I had to stop architect‑noodling and choose a direction. Architects can’t sit on the fence forever – it’s uncomfortable, and eventually someone asks for a delivery date.
My priorities for the proof‑of‑concept were:
- Avoid sending confidential data to the cloud unless absolutely necessary.
- Avoid LLM token costs (because genealogy fans ask a lot of questions).
- Prove the value proposition before worrying about fancy cloud scaling.
- Keep the door open for future approaches like MCP‑based skills.
With all that in mind, I chose the approach that keeps data local, avoids cloud LLMs, and lets me iterate quickly without bankrupting myself or my users.
Part II will dive into how the flow works when users want to change their GEDCOM, because nothing says “fun weekend” like editing 19th‑century birth records.
Next part: Generative AI for Genealogy – Part II
