This follows on from: Generative AI for Genealogy – Part VI
How to See What Your AI Is Really Doing (Instead of What You Hope It’s Doing)
At this point in the series, we’ve covered enough of the platform’s inner workings that it’s time to address a slightly uncomfortable truth: your AI is not doing what you think it’s doing. It’s doing what you told it to do, plus whatever it hallucinated in the margins – and unless you have proper observability, you’re basically flying a 747 with the cockpit lights turned off and a polite but confused co‑pilot mumbling, “I think we’re over Belgium?”
So today’s chapter is all about seeing inside the box. Not metaphorically. Literally. Logs, traces, prompts, decisions, the whole messy sausage‑making process.
But before we dive in, let’s define two terms that will keep popping up like genealogy‑themed whack‑a‑moles:
- Observability: The ability to track the entire journey from Ask → Process → Output, and to do so in a format that a human can understand without needing a stiff drink.
- Orchestration: The conceptual flow of steps, decisions, and conditional branches that make the system behave like a well‑conducted symphony rather than a toddler with a tambourine.
Up to now, we’ve looked at individual components. But to appreciate why observability matters, it helps to zoom out and see the whole contraption.
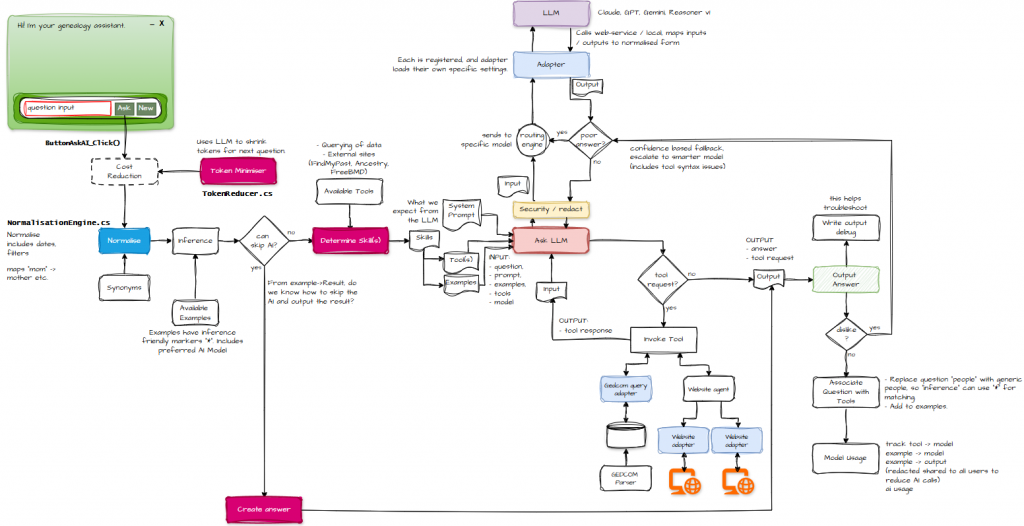
This diagram is the “big picture”, the entire Rube Goldberg machine of routing, prompting, tool usage, and error‑prone LLM reasoning. And yes, I hard‑coded the whole thing. Not because I enjoy pain (although the evidence suggests otherwise), but because:
- I wanted to understand why things work, not just use a framework and hope for the best.
- It gave me an excuse to write more C#.
- It was faster for a proof‑of‑concept.
- I hadn’t yet realised there were cleaner approaches.
If you use a framework like LangChain or LangGraph, you get orchestration and traceability baked in. They give you a nice, structured flow with decision points, retries, and logs. My approach, on the other hand, was more “duct tape and determination.” But regardless of how you glue your system together, one truth remains:
There will be times you need to see inside the box.
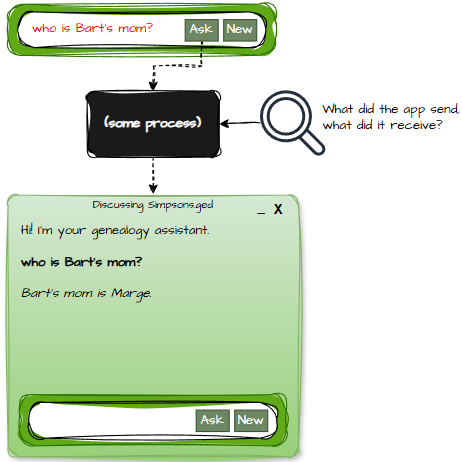
Without an orchestration subsystem, every step is tightly chained to the next. Any one of them can fail, misinterpret, or simply decide that today is not the day it wants to cooperate. When something goes wrong, and it will, you need to know:
- What prompt did the LLM actually receive?
- Did the SYSTEM/USER/ASSISTANT roles get passed correctly?
- Did the model decide to “fix” your formatting because it felt creative?
- Did a hidden control character sneak in like a gremlin?
Before I added observability, I was spelunking through GPT4All’s Chats → Server Chat panel, wrestling with scrollbars that behaved like they were coded by someone who hates scrollbars. I adore GPT4All for the local‑LLM magic, but the UI… let’s just say it builds character.
So I built a class that manages all of this regardless of which LLM is being used. The orchestrator can talk to multiple models at once, and the user never knows. But I need to know. And that means detailed, chronological, readable logs.
Not pretty logs. Not polished logs. But logs that tell the truth.
