This follows on from: Generative AI for Genealogy – Part XII
The One Where We Finally Fight Back
It was time. Time to fight back against the GPT trolling. And how did I choose to do it? By… following instructions given to me by GPT.
Yes. The irony is not lost on me.
To set the stage, let’s begin with a cultural artefact as enduring as Stonehenge, but with better hair: The Simpsons™ family tree.
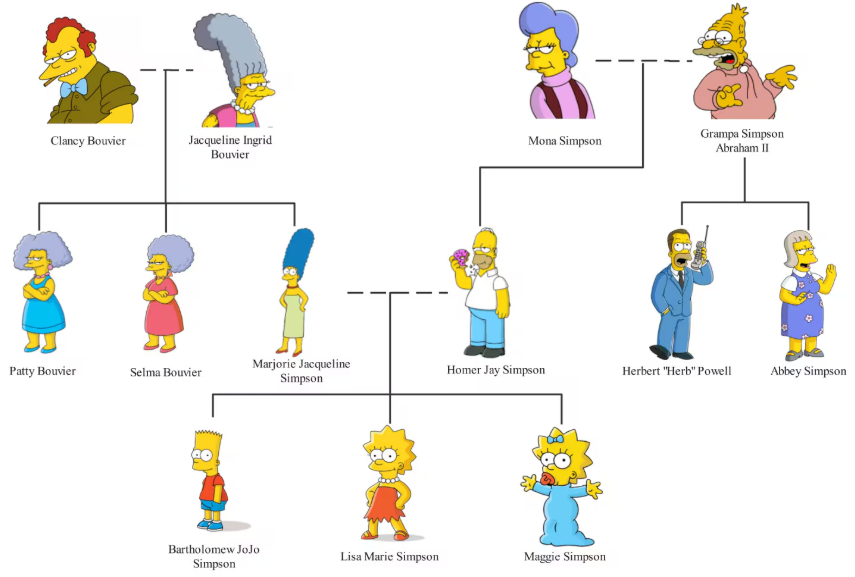
Source of image (EXTERNAL WEBSITE: edrawmax.wondershare.com)
The Simpsons is one of those rare shows that has been running since the dawn of civilisation, yet somehow remains funny. An achievement matched only by the fact that people still argue about pineapple on pizza.
If you’ve been following this series, you’ll remember that I previously failed — spectacularly — because I made the rookie mistake of asking an LLM a factual question and expecting a factual answer. Honestly, it was like asking a politician for a straight response. Or a president. Ahem.
That reminds me: I still need to check what’s happening in “Iceland”.
Anyway, the missing ingredient in my earlier attempts was decomposition — or as I now lovingly call it, chunking.
A Simple Question That Isn’t Simple at All
Let’s take a very straightforward example:
“Who are Homer’s parents? Are they also Marge’s parents?”
Now, unless you’re Ralph Wiggum, you already know the answer is “no”. (If you are Ralph Wiggum, thank you for reading my blog. Please don’t eat it.)
There are many ways to answer this question:
- Ask the show’s creators
- Phone a friend
- Look at the diagram above
- Or, if you’re feeling brave, ask an LLM
But from the LLM’s perspective, it needs data — and it can get that data in a couple of ways:
- Call a tool to fetch Homer’s parents and Marge’s parents, then compare
- Call a tool to fetch Homer’s siblings and check whether Marge appears
Reasoner v1 chose option 1, which required two tool calls and a comparison. Why? Because it apparently wanted to eat my tokens like Homer eats doughnuts.
Mileage may vary when I eventually throw it out and replace it with something else.
But for now, let’s stick with what it did.
Teaching the Model to Break Things Down (Without Breaking Me)
I gave the LLM a prompt instructing it to break the question into chunks — each chunk corresponding to exactly one skill. I also forced it to output JSON, because if there’s one thing LLMs respect, it’s a rigidly enforced format.
And to its credit, the model complied. All that training paid off. It stayed on the path. It didn’t wander off into a creative reinterpretation of The Simpsons universe.
The JSON output looked something like this:
[
{
"id": "step1",
"skill": "parentage_ancestry",
"question": "Who are Homer's parents?",
"depends_on": [],
"requires_entities": ["person"],
"can_fail": true,
"on_fail": "return_partial",
"notes": ""
},
{
"id": "step2",
"skill": "parentage_ancestry",
"question": "Who are Marge's parents?",
"depends_on": [],
"requires_entities": ["person"],
"can_fail": true,
"on_fail": "return_partial",
"notes": ""
},
{
"id": "step3",
"skill": "comparison",
"question": "Are Homer and Marge's parents the same?",
"depends_on": ["step1", "step2"],
"requires_entities": ["person1", "person2"],
"can_fail": true,
"on_fail": "return_partial",
"notes": "Uses results from steps 1 and 2"
}
]Pretty neat, right? It was one of those rare moments where you don’t feel the crushing disappointment of watching an LLM gleefully waste your time.
Even better, the JSON included a dependency graph via depends_on.
This is the model’s way of saying:
- Steps 1 and 2 can run in parallel
- But don’t even think about running step 3 until step 2 is done
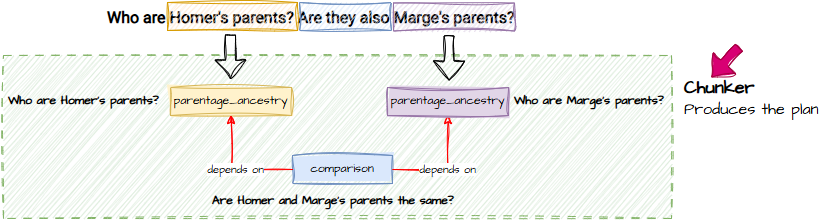
Enter: The Resolver (No Simpsons Were Harmed)
Now we have:
- Distinct sub‑questions
- A clear execution order
- A dependency graph that tells us what can run concurrently
This execution phase is what I call the Resolver.
Once the Resolver finishes, we’re left with a set of question/answer pairs — but not a final answer. Something still needs to stitch everything together into a coherent response.
That something is the Final Answerer.
Why that name? Because it answers… finally. (We’re not overthinking this.)
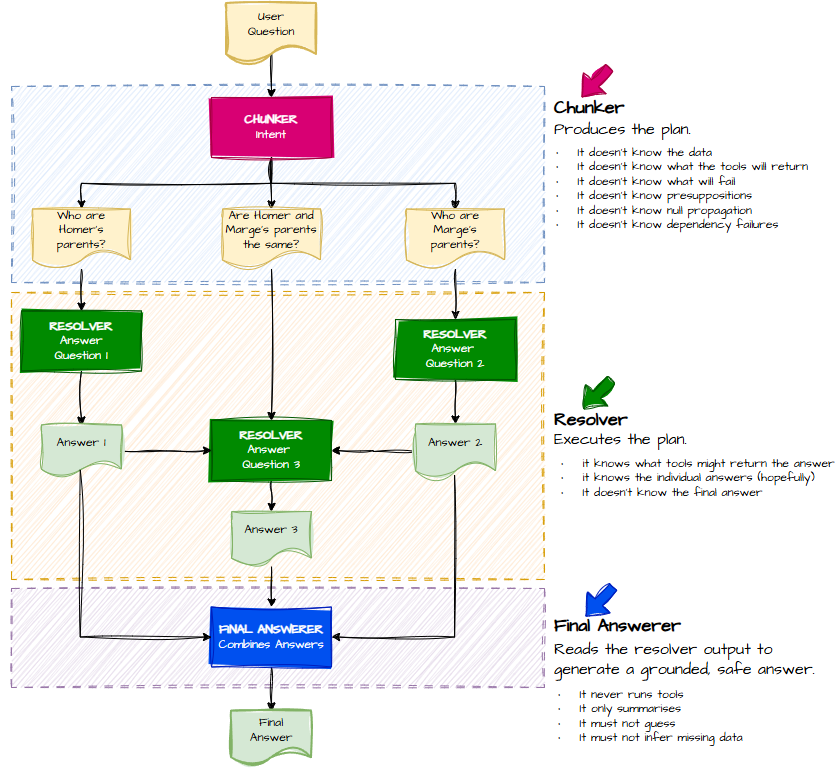
GPT even reminded itself of the key principles:
- Segregation of concerns
- Accuracy over creativity
- Don’t run tools you’re not supposed to run
Honestly, if only humans followed instructions this well.
The Flow Chart of Loopiness
Of course, nothing in AI is ever linear. There are loops. There are checks. There are classifiers. There are moments where you ask yourself “how much more?”.
So I drew a flow chart.
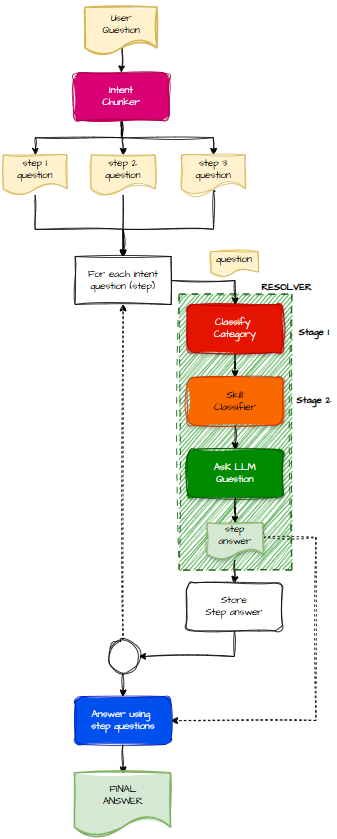
This whole approach is known as multi‑intent classification (compositional). It’s perfect when:
- You want natural, conversational queries
- You want to support compound questions
- You want to chain skills
- You want a richer user experience
And genealogy questions are full of compound intent:
- “Who were his parents and where were they living?”
- “How many children did they have and when was the eldest born?”
- “Who did his sister marry and where did they move afterward?”
When I started this project, I never imagined an LLM could handle this. Yet here we are.
My App Doing Exactly That
Here’s my app showing the decomposition and dependency graph:
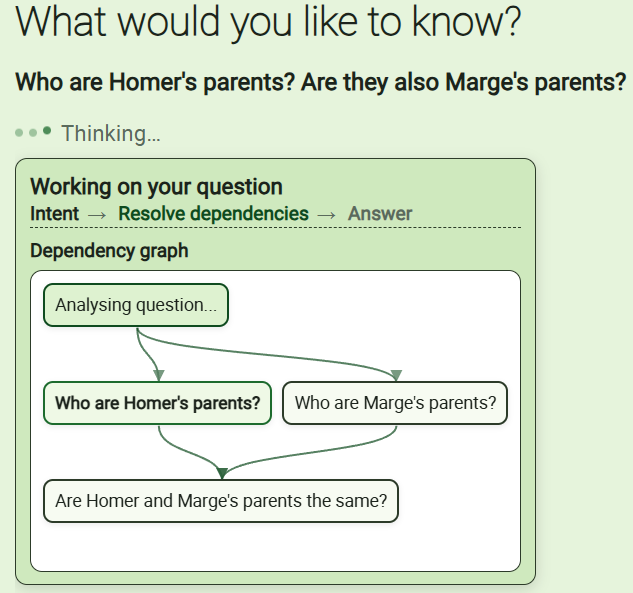
And here it is again, but now with the first two questions answered:
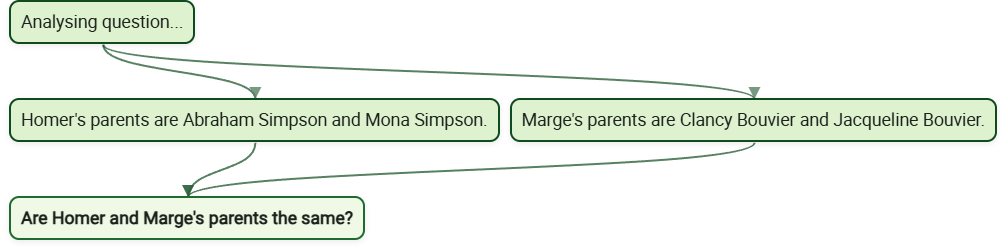
And finally, the stitched‑together answer:
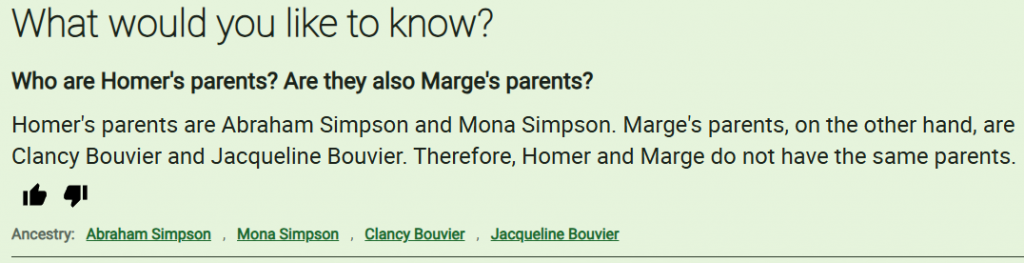
What I Actually Built
I already had an engine that could turn a single question into an answer using skills. To make it handle compound questions, all I needed to add was:
- An LLM call at the start to decompose the question
- A loop that runs my engine for each sub‑question
- An LLM call at the end to assemble the final answer
Plus a UI, because GPT4All runs slower than a sloth on a bank holiday.
Wrapping Up
If there’s one thing I hope you take from today’s post, it’s this:
Avoiding hallucinations doesn’t require a PhD in AI. Just a few simple techniques, a bit of structure, and the willingness to let the LLM do the boring decomposition work.
And maybe a Simpsons family tree.
The next instalment is here.
