If you haven’t read my previous post on Pong, it might help, but don’t feel obligated!
It’s time to make a smarter Pong.
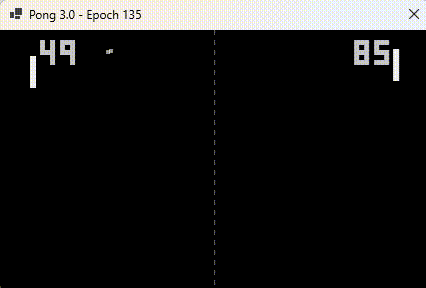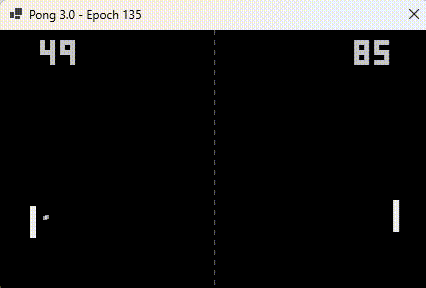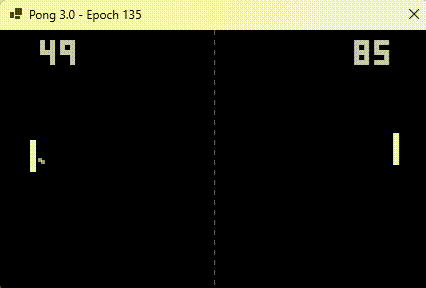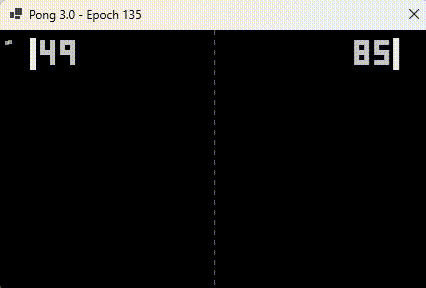
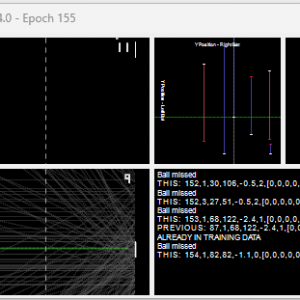
This version “learns as it plays“.
Watching it so chilled is disconcerting to watch, especially when the ball bounces off the walls. It’s learnt where the ball is going to end up as soon as it leaves the opponent’s bat, no matter how many bounces!
- The player on the left is AI
- The player on the right is my “Pong trainer”
Notice the “dead zone” that I mentioned in the previous post, where the bat is intentionally stopped from blocking shots. AI loses because the trainer placed it in an impossible-to-reach position.
The shocking part is that it moves the bat not in response to the ball, but where the ball was when the opponent hit it and the speed of deflection.
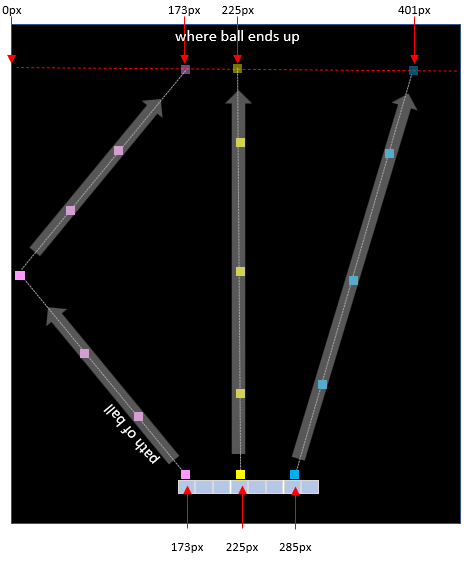
A few examples to prove that statement…
- If the bat is at X=225px, and it hits the ball in the left zone of the bat (173px), then the ball after hitting a wall will arrive at 173px.
- If the bat is at X=225px, and it hits the ball in the centre zone of the bat (225px), then the ball will go up with no X change and thus arrive at 225px.
- If the bat is at X=225px, and it hits the ball in the 2nd to right zone of the bat (285px), then the ball will go diagonally and arrive at 401px.
Although this is one of those “back-propagate” apps I loathe to call AI/ML, for a change, it is using multiple hidden layers and a reasonable example of improving as it plays (as opposed to training it to perfection). I like that aspect!
If you’ve read a number of my posts, you’ll know I am honest about how things work, and to be clear what has been achieved here is the ability to position the bat without ball tracking as it moves. It is working out from when the opposition hits the ball, where it needs to position the bat.
When you watch it, once trained it always hits the ball perpendicular – that’s because Ybat=Yball.
This solves one of the problems I called out previously – the prediction of where the ball will reach the goal line. It is not attempting to resolve the issue of where on the bat is the best placed to win – 3.0 proves that the concept of prediction works.
Before we dive into code, let’s discuss the “trainer”. For the smart folks out there, one could make training data with mathematics. I chose the lazy way. Rather than hurt my brain, I made the right-hand player simply attempt to make Ybat=Yball. This works fine as per my first Pong post until one realises the ball moves quicker than the bat.
That being said the trainer enabled the “AI” to learn without me personally having to play lots of games!
Neural Network Configuration
I’ve used a perceptron network, with TANH as an activation function.
- Inputs: 4
- Y position of the opponent’s bat / height of the tennis court
- Y position of the ball when it hits the opponent’s bat / height of the tennis court
- horizontal speed of the ball when it hits the opponent’s bat / 10
- vertical speed of the ball when it hits the opponent’s bat / 10
- Hidden:
- 4 layers x 4
- Output: 1
- The Y coordinate to position the centre of the bat.
I’ve read various articles on how many neurons, and layers. I experimented, and am happy with 4 x 4 hidden. Does it work with less? Feel free to experiment, and comment.
Because this learns from data, I’ve taken the approach of writing the training data to a file that it then reads and backpropagates upon start-up.
Training The Network
The “game” starts with a random aimed ball thrown from the centre to the “trainer”, who smacks the ball to the AI.
Before the trainer returns the ball it creates a “TrainingDataItem” object and populates it with the important data required to learn.
currentTrainingDataItem = new TrainingDataItem
{
YPositionOfTheBallWhenItHitsBat = ball.Y, // this impacts where it hit with respect to bat, and therefore return angle
YPositionOfOppositionsBat = batOnTheRightControlledByHumanOrTrainer.Y,
SpeedOfTheBallWhenItHitsBatX = ball.dx,
SpeedOfTheBallWhenItHitsBatY = ball.dy,
// the one below is stored when it reaches the "left" bat / goal line.
YPositionOfTheBallWhenItArrivesOnLeftBatLine = -1
};
Notice the “-1”. It doesn’t know where the ball is going to end up. If we wanted to, we could derive a formula to compute it. we divide the distance between the two bats by the ball.dx (velocity horizontally) giving us how many “ticks” the timer would use to move the ball. We know for each tick, it moves ball.dy vertically. We can’t simply multiply the ticks by ball.dy, because it doesn’t allow for bouncing off walls. We could work around that, but this isn’t a blog for mathematics enthusiasts.
When the ball reaches the left, if the ball is between the top/bottom of the bat we store the ball position in YPositionOfTheBallWhenItArrivesOnLeftBatLine, and store the training data.
// if "yposition" == -1, then we haven't stored the position, and need to do so then save the training data.
if (currentTrainingDataItem is not null && currentTrainingDataItem.YPositionOfTheBallWhenItArrivesOnLeftBatLine == -1)
{
currentTrainingDataItem.YPositionOfTheBallWhenItArrivesOnLeftBatLine = ball.Y;
// don't save ones that end up in the dead-zone. No point in learning this accurately.
if (ball.Y > Bat.c_deadZone + Bat.c_halfTheBatLength && ball.Y < pictureBoxDisplay.Height - Bat.c_deadZone - Bat.c_halfTheBatLength)
{
TrainingDataItem.AddToTrainingData(currentTrainingDataItem);
}
}
Because there is a reasonable chance of the same shot being played, we use a Hashmap to avoid adding duplicate data.
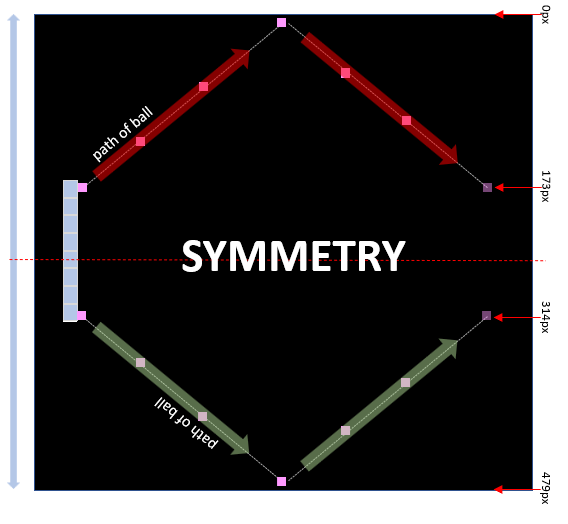
There is a learning optimisation (not applied) which is recognising symmetry – if you divide the screen horizontally in the middle, the behaviour top and bottom are identical (green vs. red path) but inverted. To speed up training, one can add Height minus bat / region hit / result, and invert “dy”.
Of course you are smart enough to think that too, but good luck getting AI to work that out…
One technique that I found works well, is calling Train() during each frame. This means that backpropagation occurs very frequently and therefore it learns more quickly. I also wanted a pause after a ball goes out of play, to delay it I call Train() repeatedly. It doesn’t provide a fixed time, but it doesn’t guarantee the AI learns from mistakes quicker. I leave it to the reader to change that to be within a timed loop (e.g. when a fixed time is elapsed, it stops training).
As usual, the app has some hidden key presses:
- “P” pauses the game
- “S” steps through different speeds
- “Q” is the obligatory “quiet” mode, where it plays without painting anything on the screen for faster learning.
- “A” toggles “auto mode”. When turned off, the cursor moving over the game moves the bat. i.e. you play. When turned on, the trainer mode is running, and it moves the bat.
The source code for this can be found on GitHub.
Before anyone posts that it’s easy to beat, I’d like to remind you what I wrote earlier “once trained it always hits the ball perpendicular”, which should never win. Once we’ve finished this tracking part, we will need to implement the targeting part.
Next, we’ll combine this with “seeing”, to finally complete the first problem in a semi-intelligent way. I hope you found this post interesting and worth the read!
Pong 4.0 will be coming soon! (Sorry for the wait).