Reacting to pixels in a display
Many interesting AI articles focus on the classification of images, even if the math is crazy. We need to do that too, after all when you see certain frames of the CartPole you need to steer left, and for others, you need to steer right.
Whilst it is a classification, it isn’t the same task as recognising different images and grouping them. This is where I believe convolutions do not benefit the task at hand.
Breaking the problem down, we can generalise and say that for each unique image, it has a tag “0” (left) or “1” (right).
If it were that easy, then I wouldn’t have spent stupid amounts of time on this.
The reality is that a single image may be left or right, depending on the frame that precedes it, because the action you take depends on the directionality of the cart and pole, or even more so the velocity of the pole…
With 2 frames, you can tell the direction of the pole, the more frames, the better in theory you can infer velocity. However, if you’ve played the game, you’ll appreciate that humans don’t require absolutes. Most of us are surprisingly efficient learners.
To give you a better feel for optimum play, the modified user version provides on-screen arrows when the user plays. If you press the correct arrow key when it illuminates, the higher your score will be. With good reaction times, you’ll get 501.
Maybe this little app will help you come on the journey with me?
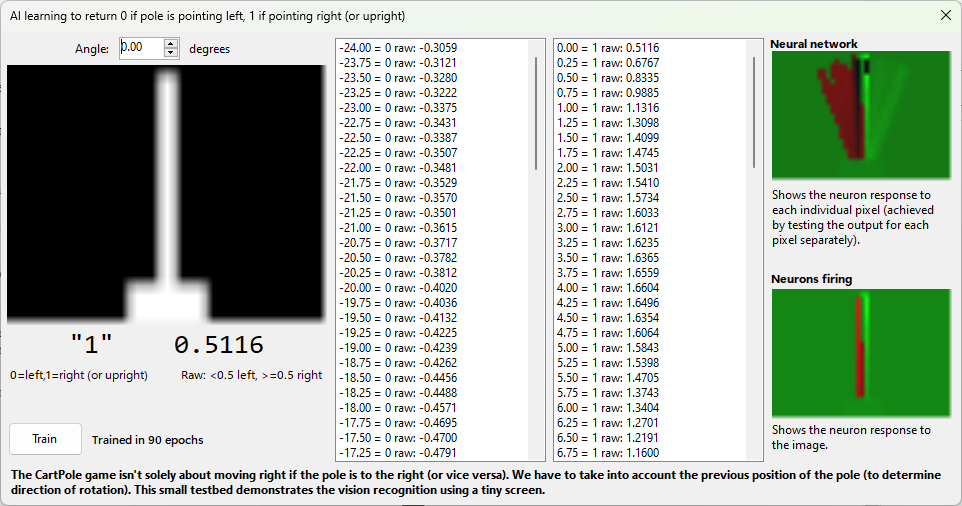
Lots of visual stuff, I’ll try to explain the idea, and hopefully, you’ll be able to appreciate my autistic mind.
For each angle, we generate a pretend pole+cart that is 32×26 pixels (looking very TRS-80 style, thanks to the zoom above).
We create a neural network with inputs (the pixels) attached to a single output. The latter is trained to return 0/1 depending on whether the pole is pointing left or right.
When you first run it, the two charts on the right are black images. This is where I chose to buck a trend in the name of more meaningful charts. I have played with Xavier defaults and gradient clipping, but like it or not, random seeding of the weightings ends up with weights that need to be eliminated (no pixel ever touches those neurons).
The top right image shows how after training, the neural network chose to attribute negative values to the pixels on the left of vertical, and positive to the right. Simple – right?
It is but, you’ve got to remember the output is the SUM( of each pixel x associated weight ) + bias, ignoring the activation function. The only way it can influence “0” or “1” categorisation is by the sum being < 0.5 (left) or >= 0.5 (right).
I hope you appreciate how I enabled you to see into the neural network. It does so by individually setting each pixel to “1” and the rest to zero, and measuring the neural network output. It works nicely.
The bottom right chart shows how the pole pixels overlay onto the top image, and which +/- make up the overall value.
Maybe this helps?
As we rotate left to right, you’ll notice the bottom righthand corner go from a mass of red (-) to green (+). That’s why it is capable of differentiating between left and right!
You’ll find that application on my GitHub.
I decided to get a little more “current” and use the SELU activation function, as it is less prone to vanishing gradients.
If you’re curious how I trained it (which is fairly instantly), take a look at the code. If you’re too busy for that, the approach is
- Backpropagate for angles between -24 and +24 degrees.
- Until trained
- Pick a random angle between 0 and +/-24 degrees.
- Loop
- angle = -angle (flip sign)
- Add a random amount to the angle (in the same sign as it)
- If the angle is now outside the 24 degrees, break out the loop
- Retrieve the image for that angle
- Backpropagate image + expected direction
“trained” is defined as images of all angles returning their correct directions, and
“backpropagate” above means to backpropagate, check the result is correct and repeat the backpropagate step until it is correct.
With this blog post, you’ve read how simply feeding pixels into a neural network can classify items.
I am not asking you to abandon all the clever techniques, with convolutions, pooling etc. Ask yourself if you’re cracking a walnut with a steam roller, and whether there is a simpler approach that yields the desired outcome… Always weigh up pros and cons.
That’s all for this post, I hope to follow up soon with the finished video CartPole application in a longer post.