The Diagnosis: Small Models Are Confidently Wrong
Eventually GPT sighed (metaphorically) and said:
Yeah, that behaviour from both 1B and 3B is exactly the kind of “confidently wrong” you get when you push them into genuine semantic work. You’re not doing anything wrong – the models just aren’t reliably capable of what you’re asking.
It went on:
- 1B/3B models don’t have stable semantic boundaries
- “Same type of information” is too abstract
- They latch onto the wrong features
- They explain correctly but conclude incorrectly
- You can’t prompt your way out of this
In other words:
I was trying to use a butter knife to cut steel.
And the butter knife was very proud of itself.
To illustrate the point, here’s one of the more disturbing pieces of logic Llama produced:
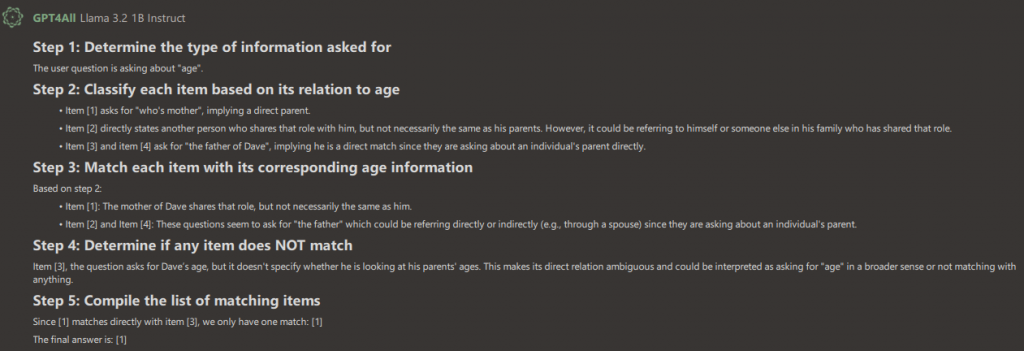
If that doesn’t keep you awake at night, nothing will.
And just to add insult to injury, after restarting GPT4All, the same question sent Llama into a 70‑iteration loop of nonsense.

This was with:
- Temperature: 0
- Top‑P: 0
- Min‑P: 1
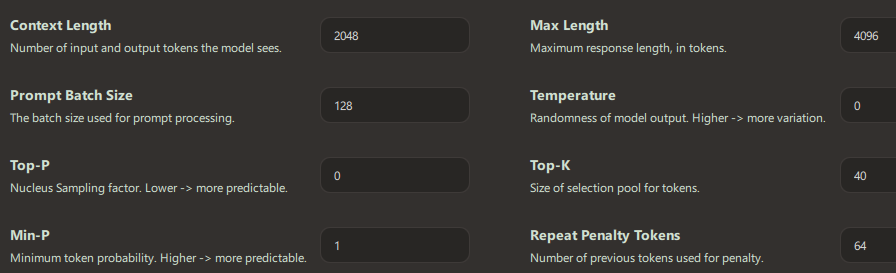
So no, this wasn’t hallucination. This was deterministic stupidity.
