One of the classic ML benchmarks is the MNIST digits with industry gurus like Yann LeCun.
That benchmark was around 1998 I think, and about “handwritten” digits.
Great. tbh I don’t have much of a need for handwritten digits. For any printed text I have software like the PowerToys TextExtractor. If I had a bigger need, there’s software like ABBYY commercially and freeware Tesseract.
That didn’t stop me from trying something that may be pointless for a thought experiment.
I have 231 or so useful fonts installed. If I write the digits 0-9 in each font at 14×14 pixel size and associate them with their respective number, can I train ML to reliably learn them with 100% accuracy? None of this less than 100% stuff low bar others accept, I am not settling for less.
For those of you more experienced please don’t mention “training” vs. “test” data and how you train on part of the data and test on the rest. Yeah, I know, but…
You’re probably thinking I am nuts. So I challenge you to tell me what digit this is?
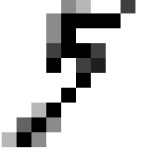
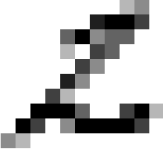
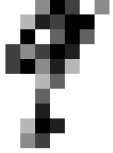
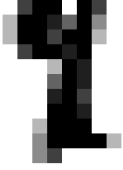

Feeling so smart now? The last one isn’t an 8. I suspect you will fail on all 5 without “cheating”
My neural network knows and gets it right every time.
I chose a grey scale 14px * 14px image to make it difficult but also reduce the size of the network. Once you shrink letters the “details” that enable you to distinguish are lost.
Let’s look at what is behind it.
I created a perceptron neural network using backpropagation.
- Input: 14×14 (size of an image),
- hidden: 30, 30, 30
- output: 1 (0-9 scaled n/10).
The “.ai” file containing the weightings and bias is made up of 7802 numbers.
100% precision: 231 fonts x 10 digits x 14×14 pixels = 665,280 data-points. Here it is!
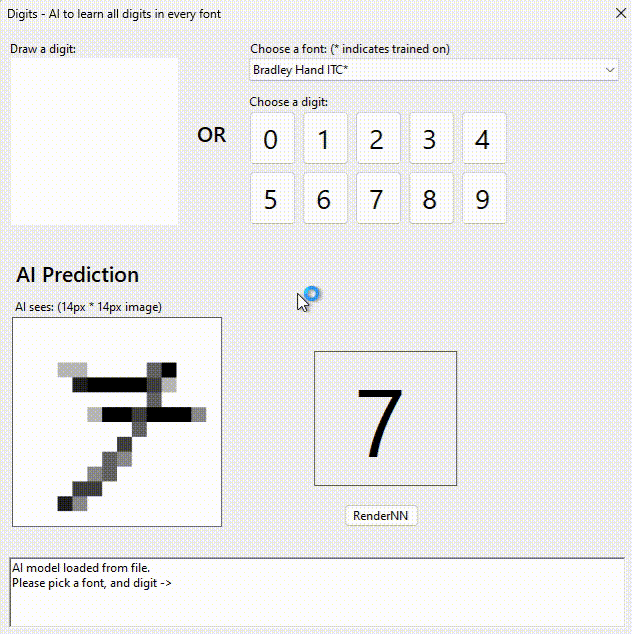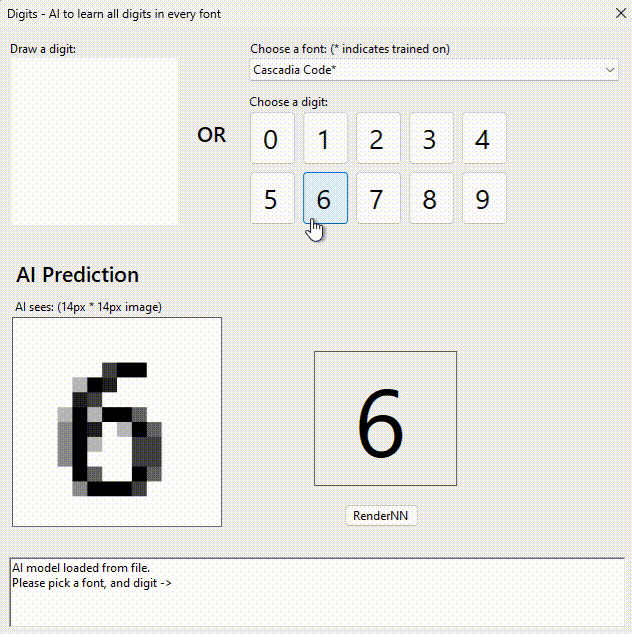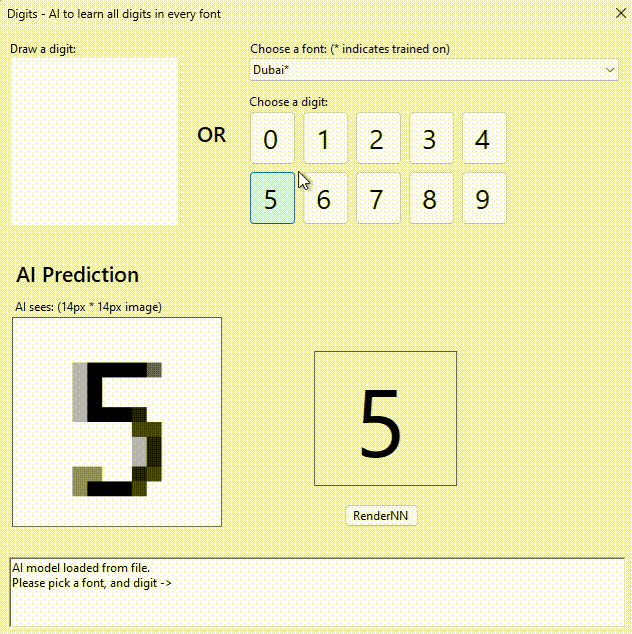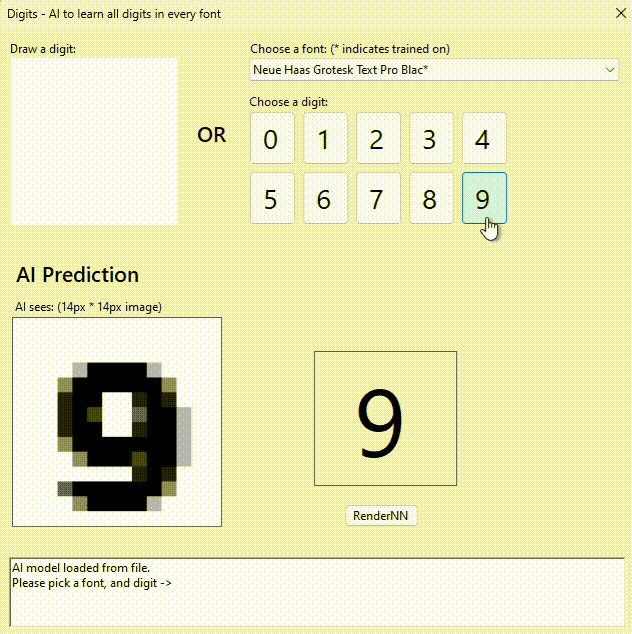
I pasted all the digits it outputs into MSWord and saved as a PDF for you. If you zoom, you can see some of them are bizarre.
Maybe I am easy to please, but I think that’s quite cool.
Preparing Training Data
Training data was created using this code; you’ll notice I excluded a few fonts – they don’t have digits. It enumerates the fonts and creates an “object” to write the digit to a bitmap.
/// <summary>
/// Render all 10 digits (0..9) for each font.
/// </summary>
private void RenderEachDigitForAllTheFonts()
{
int numberOfFonts = 300;
int cnt = 0;
InstalledFontCollection col = new();
foreach (FontFamily fa in col.Families)
{
// avoid, or find out why you should have avoided them!
if (fa.Name.Contains("Symbol") ||
fa.Name.Contains("Blackadder ITC") ||
fa.Name.Contains("MDL2 Assets") ||
fa.Name.Contains("Palace Script MT") ||
fa.Name.Contains("Icons") ||
fa.Name.Contains("MT Extra") ||
fa.Name.Contains("MS Outlook") ||
fa.Name.Contains("Marlett") ||
fa.Name.Contains("Parchment") ||
fa.Name.Contains("MS Reference Specialty") ||
fa.Name.Contains("dings") ||
fa.Name.Contains("Rage Italic") ||
fa.Name.Contains("Playbill") ||
fa.Name.Contains("Snap ITC") ||
fa.Name.Contains("Kunstler Script")) continue; // symbols are totally different to digit.
++cnt;
comboBoxFont.Items.Add(fa.Name + (cnt <= numberOfFonts ? "*" : ""));
for (int i = 0; i < 10; i++)
{
if (!digitsToOCR.ContainsKey(i)) digitsToOCR.Add(i, new());
if (cnt <= numberOfFonts) digitsToOCR[i].Add(new DigitToOCR(i, fa.Name));
}
}
comboBoxFont.SelectedIndex = 0;
}
With a font and its particular digit representation we need to “draw” it to a Bitmap, which it does with:
using Font font = new(fontName, 10); float imgSize = 14; image = new((int)imgSize, (int)imgSize); using Graphics g = Graphics.FromImage(image); g.Clear(Color.Black); // center the "digit" on the image SizeF size = g.MeasureString(digit.ToString(), font); GetRealSize(digit, font, size, out PointF offset); g.DrawString( digit.ToString(), font, Brushes.White, new PointF(imgSize / 2 - size.Width / 2 - offset.X, imgSize / 2 - size.Height / 2 - offset.Y)); g.Flush();
But that’s not what we store, there is a bit in the middle GetRealSize(). This method draws it separately, measures it then provides an offset. Sound nuts? It is kind of, but what I found was that DrawString() doesn’t guarantee the drawing is precisely centred because of the way it measures fonts. It allows for “descenders” like “y” or “g”, and results in vertically misaligned digits.
I don’t however resize digits that are smaller to make their size conformant. It didn’t need it to work.
This is an area of curiosity. Would it learn better if we stretched each digit to match 14×14?
The neural net could use ARGB, but that is a little inefficient. If we’ve written white text on black, then everything is grey scale (one byte to store pixels).
I have an AIPixelsFromImage that turns the pixels to 0..1 (from 0..255) returning a double[] with all the pixels. We don’t need a 2d array, the neural network doesn’t need that level of info. Because the input is ARGB, it takes a byte then skips to the next pixel (each it 4 bytes). e.g.


internal static double[] AIPixelsFromImage(Bitmap image)
{
double[] pixels = new double[14 * 14];
byte[] s_rgbValuesDisplay = DigitToOCR.CopyImageOfVideoDisplayToAnAccessibleInMemoryArray(image);
// convert 4 bytes per pixel to 1. (ARGB).
// Pixels are 255 R, 255 G, 255 B, 255 Alpha.
// We don't need to check all.
// There is a simple "grey-scale" algorithm (RGB get different weightings),
//but we're doing black/white.
for (int i = 0; i < pixels.Length; i++)
{
float pixel = (float)s_rgbValuesDisplay[i * s_bytesPerPixelDisplay] / 255;
pixels[i] = pixel;
}
return pixels;
}
The method that turns the image into byte[] containing ARGB is as follows. It’s achieved by locking the pixels and copying them before unlocking.
internal static byte[] CopyImageOfVideoDisplayToAnAccessibleInMemoryArray(Bitmap img)
{
Bitmap? s_srcDisplayBitMap = img;
BitmapData? s_srcDisplayMapData = s_srcDisplayBitMap.LockBits(new Rectangle(0, 0, s_srcDisplayBitMap.Width, s_srcDisplayBitMap.Height), ImageLockMode.ReadOnly, img.PixelFormat);
IntPtr s_srcDisplayMapDataPtr = s_srcDisplayMapData.Scan0;
int s_strideDisplay = s_srcDisplayMapData.Stride;
int s_totalLengthDisplay = Math.Abs(s_strideDisplay) * s_srcDisplayBitMap.Height;
byte[] s_rgbValuesDisplay = new byte[s_totalLengthDisplay];
System.Runtime.InteropServices.Marshal.Copy(s_srcDisplayMapDataPtr, s_rgbValuesDisplay, 0, s_totalLengthDisplay);
s_srcDisplayBitMap.UnlockBits(s_srcDisplayMapData);
return s_rgbValuesDisplay;
}
At the end of that each digit has a double[] with the grey-scale pixels.
Training the neural network
As per the usual approach –
Repeat
- For each digit 0-9
- For each font,
- backpropagate the image for the digit with expected value of digit/10
- End For
- For each font,
- End For
Until trained;
Of course we don’t literally do that forever, we do it up to 30,000 epochs after which we give up.
We also check the result after 16k epochs to see if it is trained. Before that, it is unlikely, so testing when we know it won’t have learnt, would just slow it all down. This might seem obvious, but how do you know without testing that it is trained?
Using the trained network
When the user clicks on a digit, it stores the value of the digit and fires the ComboBox event handler.
/// <summary>
/// User clicks [0]...[9], and we ask the AI to guess the digit clicked in the current font.
/// </summary>
private void ButtonDigit_Click(object sender, EventArgs e)
{
testDigit = int.Parse(((Button)sender).Text);
ComboBoxFont_SelectedIndexChanged(sender, e);
}
The event handler gets the selected font, and gets the pixels for that digit in that font – remember we cached them for training.
To guess the digit it does a FeedForward(<pixels>) and multiplies by 10 (remember training is 0-9 -> 0/10..9/10). I could have trained for a different output approach – 10 outputs (a “1” output means it thinks it matches). But if I went that approach I could have multiple probable digits. I am looking for absolutes, not probable.
/// <summary>
/// User selected a different font, ask the AI to identify the digit.
/// </summary>
private void ComboBoxFont_SelectedIndexChanged(object sender, EventArgs e)
{
int index = (comboBoxFont.SelectedIndex);
if (index < 0) return;
string font = comboBoxFont.Items[index].ToString().TrimEnd('*');
double[] pixels = DigitToOCR.BitmapGetImage(testDigit, font, out Bitmap image);
image.Dispose();
image = DrawPixelsEnlarged(pixels, 15);
pictureBoxAISees.Image?.Dispose();
pictureBoxAISees.Image = image;
labelResult.Text = ((int)Math.Round(10 * networkGuessTheDigit.FeedForward(pixels)[0])).ToString();
}
How well does it perform for handwritten digits?
Awfully. Rather rubbish, and tbh that surprised me. I got one to match!
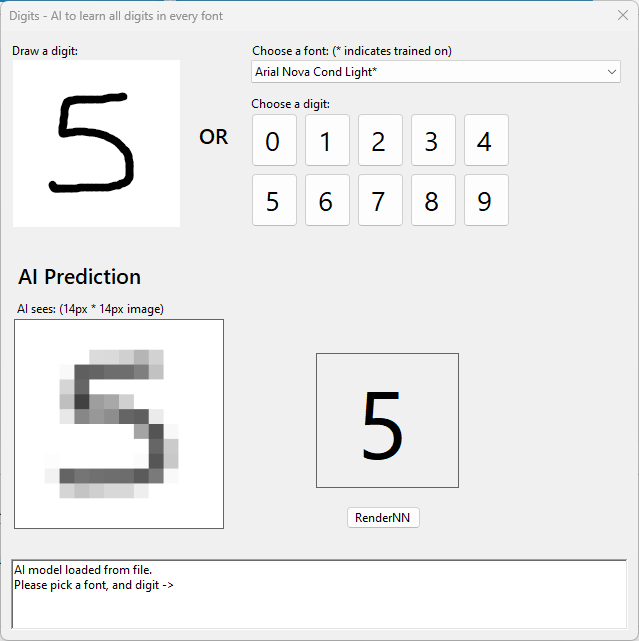
But that’s rare, look at this embarrassing result. For all 231 fonts it works, but it makes me despair a little at how my ML could be so rubbish.
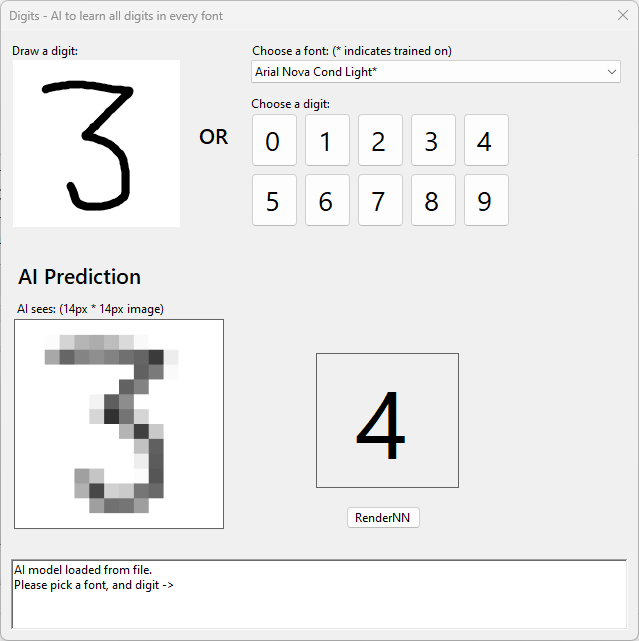
The phenomenon is not new. It’s called “over-fitting“. It precisely matches the training data but is poor for things it hasn’t seen (generalising).
Overfitting may be undesirable in a lot of use cases, but not all. My Getting pixel precision snips of records tool has occasional OCR issues using Tesseract despite being a quality font in Chrome. If I were to train a neural network on that particular font, I would firstly not need to use a 3rd party product and would have 100% accuracy. This is definitely going to be a future post.
As usual, the code for this can be found on GitHub.
You’re unlikely to win any Kaggle competition with what you just read, but I hope this post gives you ideas. Please post any feedback/comments below.