Maybe I am impressed easily, but I feel linear regression is cooler than people might think. And despite what it does, it doesn’t require much in the way of fancy programming.
Let’s take an example, in this graph where you would draw a straight line that best fits the graph.
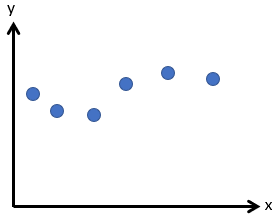
It wasn’t very difficult, was it? Having done that, you could tell me the formula to describe it.
y=ax+c
- c is where it touches the x axis when x=0, and
- a is how much it goes up or down for each unit of x.
If you didn’t learn about this in secondary school or earlier, I would be shocked.
It looked like this right?
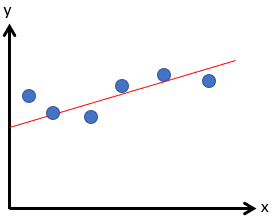
Maybe you’re thinking yes, but where’s this going?
Your brain did that without much effort. Do you know how? What was the process it followed? Most people are probably not immediately conscious of what the process is – after millions of years of evolution it’s a trivial task.
I suspect most people think to start the line somewhere between the first couple of points, ending somewhere between the last two and then make tweaks by rotating and shifting the line accordingly until it looks correct. Those autistic like me might want to measure each y and x, and calculate the line accurately rather than guess.
As great as you are, this blog is about ML (machine-learn) not YL (you-learn). So let’s solve the same problem using a neural network if you can even call it that – it has 1 input, 1 output. Through back-propagation we feed it the X and the corresponding Y. Magically it adjusts the bias and weights.
The code for this example is here on Github.
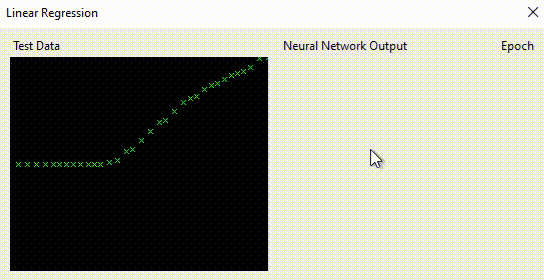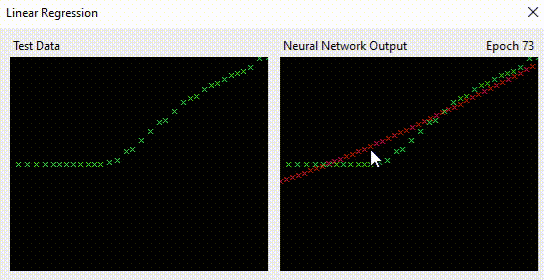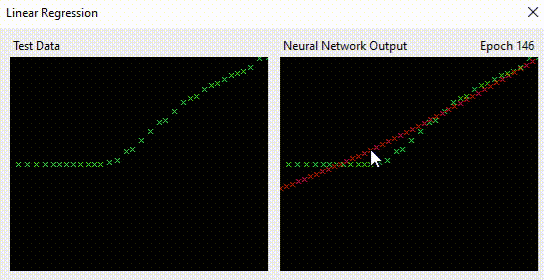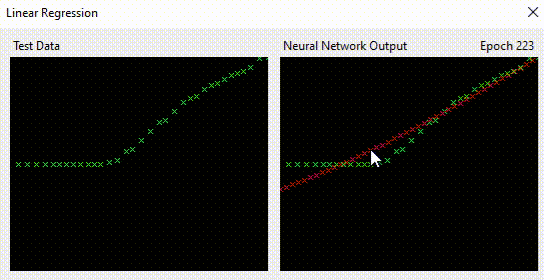
I could bet it did that quicker than you did, and I can say without fear of being challenged; it also did it more accurately.
If I wanted it to be instant I would not use a “timer” to animate it. This is very important. Important enough that pretty much all of my applications have a silent/quiet mode which enables them to perform “learning” much faster.
You might be thinking how’s that a revelation? Well, when I first built cars driving around a track I wanted to watch them learn. It was cool to see them obey the world, and improve with each generation. Then it dawned on me that it would learn a lot quicker without painting the world frame-by-frame. I was sold on the idea.
Before being dismissive and asking what is wonderful about being able to draw a line through random points, I ask you think about how it achieved it. “Using a neural network” isn’t the answer I am looking for, I’ve already told you that much.
For one example (not the screenshot above), the neural network resolves to:
double y = Math.Tanh((-0.362737709200669*x)+0.6125998143179101);
Ignoring the TANH it is y=ax+c.
I have merely described the weightings and bias as code. If you don’t understand hyperbolic tan, you’ll get something between -1…-1 regardless of the magnitude of the input to it. But X and Y on the graph weren’t 0…1; I thus had to scale them based on the width and height. As a result, the output of the neural network, unfortunately. returns a number divided by height…
foreach (Point p in pointsGreenCross) trainingData.Add(new double[] { (float)p.X / width, (float)p.Y / height});
Thus the formula for that line would be more accurately expressed as:
double y = Math.Tanh((-0.362737709200669*x/width)+0.6125998143179101)*height;
OK, but still even knowing that – how did it do it?
Training data is an X with an expected output Y. We push each training data point X through the neural network (feedforward) to get a predicted Y. We then work out the error of the prediction (output vs. expected, which is the training data point Y) and adjust the bias and weight using the following formula, where “0.01” is the learning rate.
biases -= (output-expected)*(1 - Math.Pow(output, 2)) * 0.01; weight -= (output-expected)*(1 - Math.Pow(output, 2)) * X * 0.01;
If you think about the implications –
- if output == expected we don’t adjust – because it will subtract something multiplied by 0.
- as (output-expected) tends to 0, we make smaller changes because the error difference is the multiplier
- when (output-expected) is large, the multiplier is large thus applying a much bigger change
Both adjustments are proportional to the output squared and further made 1% in magnitude. The weighting is proportional to X making it adjust more for larger values otherwise it will not come to a suitable equilibrium.
This linear regression process uses “gradient descent”.
Our example up to now is something that if you used a neural network for, I would despair. There are umpteen simpler and more efficient ways to achieve it. Replacing the neural network Train() and feedforward using this proves my point.
double bias = 0;
double weight = 0;
private void Train()
{
for (int i = 0; i < trainingData.Count; i++)
{
double[] d = trainingData[i];
double output = (weight * d[0]) + bias;
double expected = d[1];
bias -= (output - expected) * (1 - Math.Pow(output, 2)) * 0.01;
weight -= (output - expected) * (1 - Math.Pow(output, 2)) * d[0] * 0.01;
}
}
// this returns "y" for a given "x"
double y = (weight * x / width) + bias;
It’s got a fancy name and a well-known process; that’s not what makes me think it’s cool.
The code for this example is here on GitHub.
What if the points describe a wavy line?
Most humans can copy the line, but could they provide a formula that describes the line? Unless they’ve got a degree, Masters or PhD in mathematics, probably not. Working it out manually would be nuts.
Neural networks solve that so easily. With each epoch, the red crosses start to match the green crosses. It is learning the complex relationship between X and Y.
What’s the difference then between it providing straight and wavy? It’s the number of ax+c terms you give require. (in the form of neurons).
Leaving it a while longer, it now matches the data points accurately. So it has accurately now worked out a relationship between X & Y.
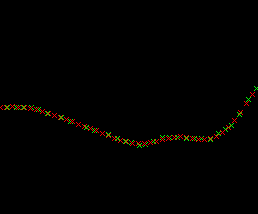
The code for this example is here on GitHub.
It was interesting experimenting with different configurations of the neural network: (this one worked best of all)
int[] AIHiddenLayers = new int[] { 1, pointsGreenCross.Count, pointsGreenCross.Count, pointsGreenCross.Count, 1 };
Try different values. For example, is it better to have multiple hidden layers OR one bigger layer like this? What’s the optimum?
int[] AIHiddenLayers = new int[] { 1, 10*pointsGreenCross.Count, 1 };
I found this worked pretty quickly finding the optimum but not always.
int[] AIHiddenLayers = new int[] { 1, 10, 10, 10, 10, 10, 1 };
If you try it and have suggestions or observations, please do comment!
Why’s something that can work out points on a line a big deal?
Because it is a way machine learning can be used to work out a relationship in the data. The approach isn’t limited to just 1 independent and 1 dependent variable, it works for many.
It can be used for things like ad spending vs. revenue or in clinical trials to predict blood pressure relative to dose. It’s not magic, but if there is a relationship it should be able to derive it.
Whilst I think it is amazingly clever of the mathematicians who worked it out and also incredibly useful, I am loathed to even put this in the machine learning category. Call me autistic, but the machine isn’t learning – it’s performing iterative refinement using feedback.
One can argue that machine learning can “solve” something difficult for a human to perform quickly. But only by adjusting the answer at near speed of light i.e., you’re using an algorithm to hone in on the answer very quickly.
PI can be calculated using the Taylor series, PI/4 = 1 – 1/3 + 1/5 – 1/7 + … each fraction makes it more accurate and therefore more decimal places – requiring iteration to refine the answer. But it too isn’t machine learning.
Maybe one has to concede that whilst mathematics figures heavily in everything, linear regression is a means to an end, for want of something better. It is unlikely to turn out to be the most optimal way to solve such use cases. But it isn’t necessarily poor because it works differently to our brain. Whilst it may even be part of all future AI; I suspect it will be more likely that a true AI will learn mathematics and design a much more efficient algorithm.
It is an area where machine without question beats biological brains and are superior for such tasks. Evolution / natural selection has not favoured brains that compute things of this nature. Being able to, is rarely going to provide a huge competitive advantage at least as far as our current times. We don’t even need to as we’ve advanced to the point that humans can make machines do it for us, which brings us full circle to this topic.
My opinion
