This post took a lot longer than I expected, and what seemed a fun idea demonstrated how I could troll myself with AI.
Upping the ante with Pong using what it “sees” proved to be much harder in practice. Never one to shy away from challenges, I did it, so I got the last laugh, even if I would strongly not recommend this as an approach.
I score this 1/10 for success thanks to the world’s least efficient AI approach (it takes a long while to be good at returning the ball). But I hope you find some of the approaches of interest if only to avoid them! The visuals might be reusable too.
AI Vision
The concept started from the idea of a camera above the game’s tennis court. The “AI” sees the bats, balls and all, and plays the game. How hard could that be?
If the screen is 430px by 262px (roughly the original game) that’s 112,660 pixels. Halving the screen in both directions is still 28,165 pixels.
In raw form, a neural network for that would have 28,165 inputs, and then we’d need to work out the optimum size and number of hidden layers combined with the best output approach.
I want this blog to be self-sufficient and not require an external code base, and most definitely not run on a single vendor GPU, so 28k pixels isn’t practical. I am not saying you couldn’t do it, but there are inherent problems and it will be slow to learn if one adopted this approach.
Optimisation 1
Such problems lead to creative thinking and there is definitely an optimisation!
i.e. the ball isn’t random, it moves in a straight line. Therefore you can predict where it will end up within seconds of it bouncing off the bat.
Proving that mathematically is not difficult. Ignoring the important fact it can bounce, the linear equation is solving the left Y for any given velocity of the ball for a known starting point. We work out the slope of the line, and where it intersects with the goal line. The challenge is discerning the velocity. What if it bounces? The same applies, the formula is a little larger. We’ll get to that in Pong 5, yes, I am not done with this.
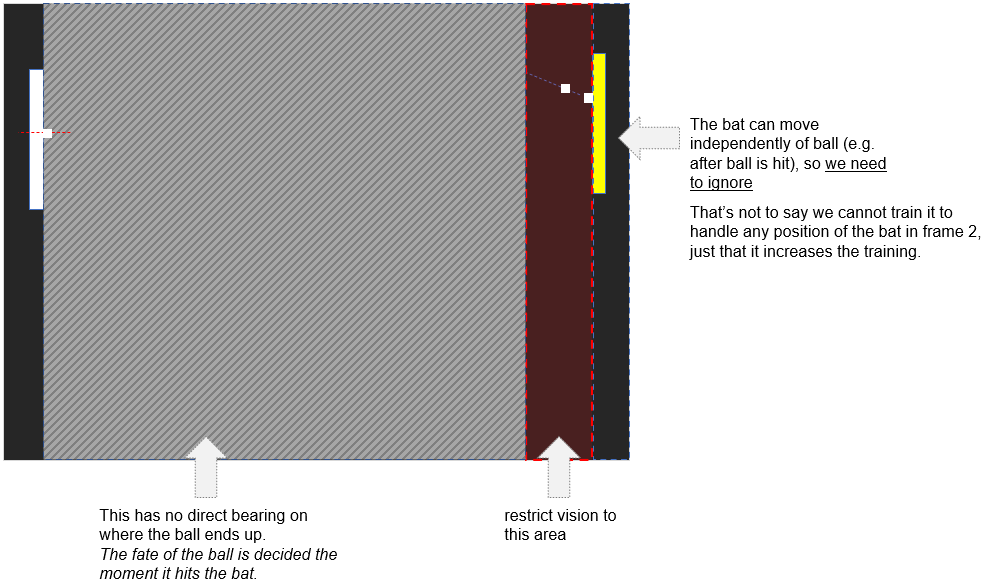
With optimisation, if the red region is 75px wide, that is still 75px (width) * 131px (height) or 9,825 pixels. Still too many pixels for my liking.
Why did I exclude the bats? And where are the scores? I am glad you asked!
If we include the bat, then our AI is going to have far more learning to do. It will need to learn to disassociate the bat from the outcome. In reality, it won’t be that smart, it’ll just learn the bat pixels go with the position of the ball.
What that amounts to is the ball in the same position and the bat repeatedly moved up or down from where it was and then training it. Why? Compare the auto-trainer to a player. From the moment the ball deflects, the bat moves with it vertically. Whereas a user might not move the bat until it hits the opposition bat, or they might put it centrally (optimal distance to return the ball).
Optimisation 2
How about the AI sees as we see? i.e. it sees a left-to-right offset and a depth (how far the ball is away).
We could represent ONE ball as 75px (horizontal) +131px (vertical) = 206px inputs to the AI. That beats 10k.
To do that we represent black pixels as 0, and white as 1. A line of pixels indicates vertically where the ball is, and a separate perpendicular that gives the depth.
Now we have a manageable number of inputs. (width eyes see vs. the height of the tennis court).
Alas, we cannot however determine the direction or velocity of the ball from one position… To do that we’ll need to track the ball over time. So snapshot the image, count a fixed number of frames and then snapshot again.
That gives us 2 points from which we can work out the angle – right?
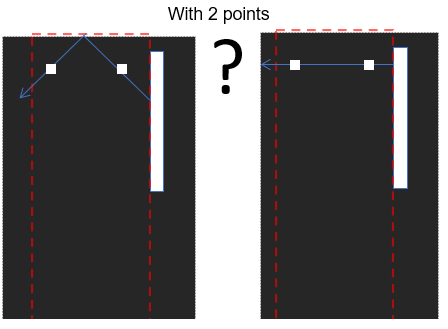
Oops, no. In this example, you cannot tell which of the two directions the ball will head. I hate to admit I did this before it dawned on me!
We can however achieve our goal with 3 ball positions, as there is no ambiguity.
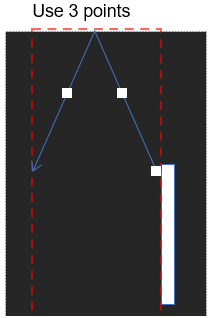
If we followed that, we have three “frames”. An additional optimisation would be to merge the 3 images. You’d have 3 points in the depth, and up to 3 pixels in the vertical direction. e.g. this.
I didn’t do that; I chose to have 3 separate frames. It’s difficult to know whether the brain stores the image in short-term memory and whether it superimposes the images, or thinks in separate frames.
Optimisation 3
I could have short-cut training by 50% using an inversion (bat Y = 131- bat Y, so ball Y = 131 – ball Y). I am kicking myself for not doing it!
What are we asking of the AI?
Not what I intended, that’s for sure. This is where understanding how something works is actually extremely important.
I thought it would not only associate the pixels with the location the ball arrives on the left but also that parallel pixels would magically be associated with a parallel course. But no. Not even close, much to my frustration.
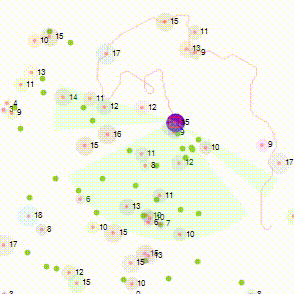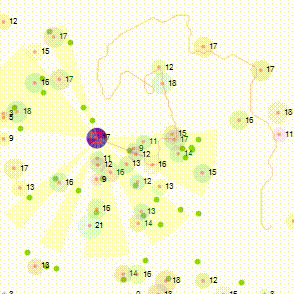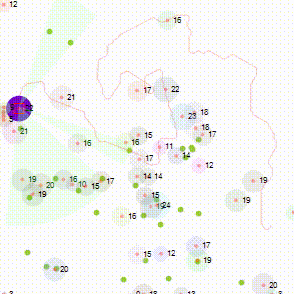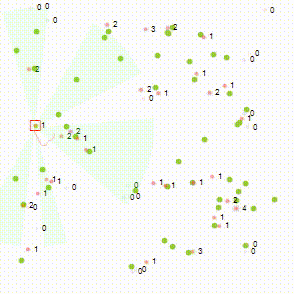
It is learning for a set input (3 frames) what the output must be. Given enough training, it will absolutely know where the bat is supposed to end up. Until that point, it is incredibly rubbish. Here’s the coverage of 5000+ training data points later.

Each line represents the path of the ball away from the bat. This live visualisation came from staring at the screen wondering about the coverage of learning. If you have an even better approach, please let me know in the comments.
It doesn’t draw any bounce, as they are not relevant to displaying coverage.
You may notice that it doesn’t even include horizontal lines for every position of the bat despite 5000+ data points. And clearly, there are a lot of diagonals it has yet to learn.
As I repeatedly call out, don’t use AI unless you have to… And if you do use AI, use it appropriately.
In this instance my intent was that AI could magically create the formula, when given 6 data points, it provided an answer, but no.
Alternative ways to learn
I am dead against this crazy approach, but imagine if this was the best approach, then AI still isn’t the right answer.
If pixel pattern 1 => left bat Y of 10, and pixel pattern 2 => left bat Y of 131, we don’t need AI. We simply create a map of the pixels to left bat Y.
Or given the pixels are 9k, we make a “sha2” hash of the pixels. In fact, for checking duplicates, I do exactly that.
So for a simpler learning approach, one creates:
Dictionary<string,int> sha2MapPixelsToLeftBatY = new();
Training is then a case of adding entries of the sha2 plus left bat Y. This is infinitely faster learning than backpropagating 5000 items of pixels.
Adding to our woes
As you can see from the above image, there are lots of lines; 5150 of them to be precise.
Things are worse than that… If it gets smart enough to return the ball, the ball accelerates by 5%. Each 5% means the pixels it is matching against are spread further apart (as the ball has travelled further in frames 2 and 3). That means a significant amount of additional training (all the angles x each velocity)…
We also have backpropagation to contend with.
- After missing ball 1, it has to learn one set of pixels and their corresponding position for the left bat.
- After missing ball 2, it has to learn two sets of pixels etc.
- After missing ball 50, it has to learn 50 sets of pixels…
The problem is that on ball 50, you can repeatedly teach it the correct position for the pixels of ball 50 and backpropagation will associate them.
But plain old backpropagation type of “learning” doesn’t work like that!
Back propagate for just ball 50, and the neural network training will impact learning for other balls. Really? Yes!
Remember back propagation adjusts ALL weightings and biases to match the item it is being trained for. If you do that, it has to impact other inputs, as you’re making it fit this one, not the others.
This is stupidly inefficient, and how a neural network has very little resemblance to a biological brain. If you practice football, did it ever make you worse at badminton or tennis? If anything the brain gets better at coordinating limbs with visual input.
Here’s how dire it is after 5792.
With Pong 3.0, we teach it a particular velocity (x,y) results in a specific left-bat position. It learns quite easily to associate, but also seems to fill in the gaps. i.e. there is a formula between ball velocity and outcome.
Although Pong 4.0, doesn’t cheat by “knowing” the velocity, the net result is that it is insanely poor at learning.
But before we look at this as dumb, let’s also consider what smart things came out of it, starting with this:
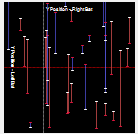
Wow, lines. Not just any lines, but meaningful lines – if you know what it is conveying.
I spent a lot of time on Pong 4, and seeing a small snippet into this doesn’t do it justice. This small chart is the culmination of 5d ideas, 3d charts and more. You’re right it’s not some flashy 3d chart, I think it’s quite cool nonetheless.
It charts the position the ball arrives at on the right (x-axis) vs. the position of the ball when it arrives on the left (y-axis).
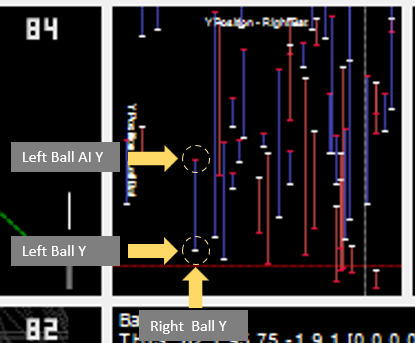
They are not points plotted but “ranges”. White is where it arrived, and red is where the AI predicted. The longer the bar the worse the AI was. The above is a plot of the training items it encountered and was inaccurate for, not an indication of how poor the training is across all inputs.
As training improves, the red line moves closer to the white line (indicating 0 difference between actual and AI prediction).
The “magic” happens every 50 or so training points. When training occurs, it plots ALL training points. And this is when you visibly see the damage backpropagation does to other pre-trained points. Below shows the lines shrinking and disappearing.
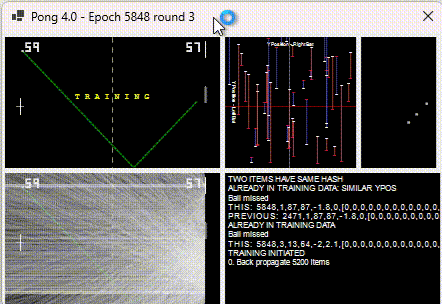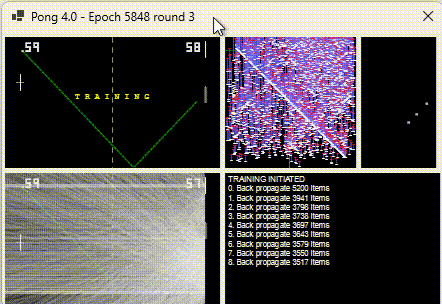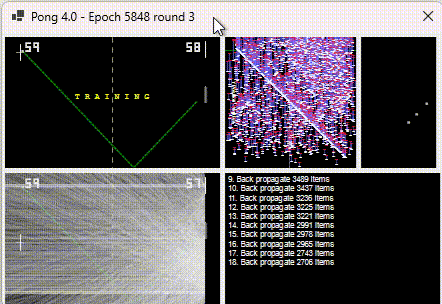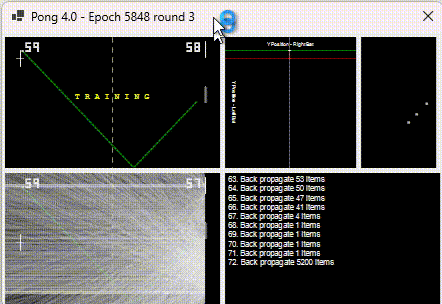
During each back-propagation, the items known to be needing training reduce.
Now, this is where I have discovered an interesting optimisation, yes, some good came of this experiment!
Conventionally, one puts ALL training points thru a backpropagation loop (or at least that was my understanding). I did that, and 4,500 training points required 13,260,684 back propagations = 13mn!
Here’s a different approach I came up with. If this idea turns out not to be original, then at least I came up with it myself. I daren’t look.
- First time -> backpropagate for all training data.
- Create an empty list ItemsNotAccurateEnough
- For each item in all training data
- Perform neural network “Feedback”, and store the result
- Compare AI output versus required output
- If not accurate enough, add the item to ItemsNotAccurateEnough. This tells us which are not returning the correct answer, and need further training.
- If ItemsNoAccurateEnough is empty, EXIT as all training data return the expected result.
- For each item in ItemsNotAccurateEnough
- Backpropagate item.
- Create empty list stillNotRight
- For each item in ItemsNotAccurateEnough
- Perform neural network “Feedback”, and store the result
- Compare AI output versus required output
- If not accurate enough, add the item to stillNotRight list
- If stillNotRight list is not empty
- Set ItemsNotAccurateEnough = stillNotRight,
- Repeat 5.
- At this point, the ones we were training are accurate, but we’ve probably messed up others in the process that we weren’t training. Repeat 2.
It is focusing on the ones it knows are wrong, correcting them, rather than needlessly doing it for ones that don’t need backpropagation.
That reduces backpropagations for the same data to 7,965,419 = 7mn. Less backpropagation => faster training.
Lesson: Backpropagation of ALL training items is inefficient. Focus on correcting those that need it.
Please note: I cannot say definitively that this lesson applies always. Before then, I’ll need to do a lot more tests.
The backpropagation concept is amazingly simple, and clever. But I cannot help feeling it’s a hugely inefficient approach and not one that biological organisms use.
Network Configuration
For what it is worth, it is defined as follows:
neuralNetworkControllingLeftBat = new(new int[] { 3 * (Config.HeightOfTennisCourtPX + Config.WidthOfEyes), 32, 1 });
INPUT: 3 frames of (width the eyes see x height of tennis court)
HIDDEN: 32
OUTPUT: 1 indicating the Y position of the bat divided by the height of the tennis court (0..1, proportional to 0..Height)
You might be wondering how I came up with 32. Trial error, and no idea of what the optimum value is. This is another area disturbing me. There’s plenty of advice about hidden neurons, but no hard and fast rule. If this wasn’t so slow to train and inefficient, I would invest time trying different values, but it just isn’t worth the effort.
I’ve uploaded Pong 4.0 to Github for those of you who are interested.
This isn’t the last attempt, with Pong 5.0 it’s still using what it sees but in a far more efficient way.
If you found this useful, please let me know in the comments below.