Training inputs, associated movement
AI Input
How do you even begin to train an AI for Space Invaders? Glad you asked!
Probably the obvious one that springs to mind is to let the AI see the screen itself, after all, that’s what a human uses. I considered it for 2 nanoseconds, then opted not to do that because 224x256px pixels require 57,344 inputs. I know ChatGPT has billions of parameters, but my laptop isn’t quite that powerful.
I did reverse that decision later, but first, let’s consider an alternative. The three options are defined in “FormAIConfig.cs“.
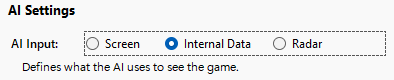
Internal Data
My first idea was to create a packet of data containing the positions of all the invaders. We need awareness bullets too, if we wish to avoid them. The AI probably also would benefit from knowing where it is relative to the bullets/invaders, and whether it is firing, or waiting to fire.
It worked, but I changed to an alternative approach, that I arrived at after discovering the Space Invader shuffle mechanism behind how the original works…
(spoiler alert)

That’s the shuffle slowed down.
Notice the ripple effect, and that only one invader moves per frame. Also notice the bottom left is the one that shuffles down, not the one that hit the wall – a little counterintuitive in my opinion.
It’s time to introduce the “reference alien” concept, that the original uses.
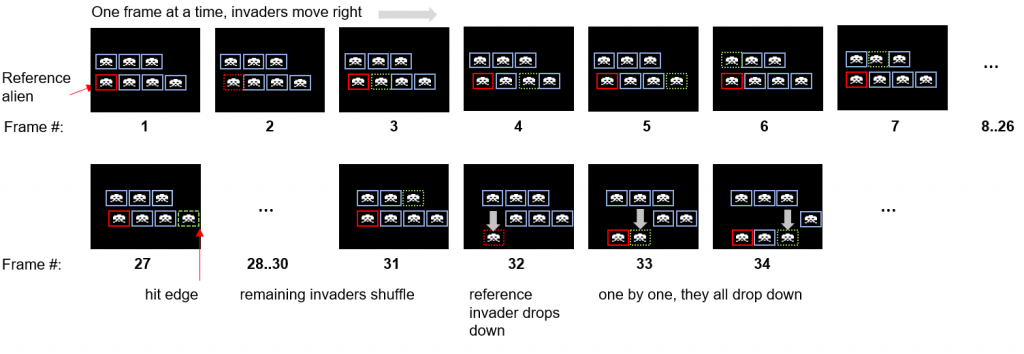
The concept of reference alien is not because coding was poor in 1978, it’s intentional. The ripple and lead alien took a while to sink in. Thanks to YouTube, I was able to mimic the behaviour.
You’ll probably think I am mad when I say the bottom left alien is the reference alien, especially as it is the most likely to get shot. Tbh, that was initially confusing for me.
In the original it does not store the position of all the aliens, it only stores which ones are alive and a single reference alien.
It seems that aliens are numbered logically 0-54, from bottom left to right, bottom to top. Alien 0 is the reference alien, no matter whether it is dead or not. To locate the position of the other aliens, it’s simple maths…
/// <summary> /// This will contain our array of 5 rows of 11 invaders. We number them as follows, in a seemingly /// upside down manner - to be consistent with the original. /// [0] is the reference alien. It doesn't matter whether that alien is alive or not, it's the reference /// and drawing is done relative to it. We don't use it to detect edge collisions, unless it is alive. /// /// 44 45 46 47 48 49 50 51 52 53 54 /// 33 34 35 36 37 38 39 40 41 42 43 /// 22 23 24 25 26 27 28 29 30 31 32 /// 11 12 13 14 15 16 17 18 19 20 21 /// 0 1 2 3 4 5 6 7 8 9 10 /// </summary> internal readonly SpaceInvader.InvaderState[] InvadersAliveState = new SpaceInvader.InvaderState[55]; /// <summary> /// On the original, the aliens are drawn relative to the reference alien. This is the reference alien. /// i.e the each frame this reference changes. It's a strange approach, but to be fair making them all /// move in the way they do without has some headaches avoided by doing this. /// </summary> internal Point referenceAlien = new(23, (SpaceInvader.Dimensions.Height + 8) * 4 +4 );
Be warned, the reference alien can be offscreen!
Instead of storing an X and Y of each alien (what do you put if they are dead?), the AI is given a 1/0 for each alive/dead alien and a single X and Y of the reference alien. The reference alien is technically the only one being tracked and moved. It moves, the next 54 follow suit, and repeat. As aliens get destroyed the same process applies, when it gets to the reference alien it moves it (regardless of alive or dead). To the user, the next live invader in the 0-54 list will move.
The other gotcha is that the aliens have a direction and a speed (that varies as mentioned previously). For the aliens, the code looks like this:
internal List<double> GetAIDataForAliens()
{
List<double> data = new();
// this provides 1/0 for each alien, indicating whether it is alive or not.
for (int i = 0; i < 55; i++)
{
data.Add(InvadersAliveState[i] == SpaceInvader.InvaderState.alive ? 1 : 0);
}
// This provides the position of the reference alien, all the alive aliens are relative to this.
// Why divide by 2x, because the reference alien could be offscreen. Example, alien 55 (top right) is the only one
// alive, as it moves left, when it reaches the left, the reference alien is 10x16 pixels left of it (offscreen).
// When it moves to the bottom, the reference alien is below the screen. (this burnt me for a while).
data.Add((double)referenceAlien.X / (2 * OriginalDataFrom1978.c_screenWidthPX));
data.Add((double)referenceAlien.Y / (2 * OriginalDataFrom1978.c_screenHeightPX));
// provide alien direction
data.Add(XDirection / 3); // the last alien moves left 2px, and right 3px. So we divide by 3 to get a value between -1 and 1.
return data;
}
What about the bullets and saucers? Fair question; the previous code is simply for the aliens and supplements a more comprehensive set of input data.
public List<double> AIGetObjectArray()
{
// where is the player located? Returned so the AI knows where it is.
List<double> data = new()
{
// it needs to know WHERE it is
playerShip.Position.X / (double)OriginalDataFrom1978.c_screenWidthPX
};
// if it is firing, AI doesn't need to know where. It either hits or doesn't
if (playerShip.BulletIsInMotion)
{
data.Add(playerShip.BulletLocation.Y / OriginalDataFrom1978.c_screenHeightPX);
}
else
{
data.Add(0); // not firing
}
// tell the AI where the invader bullets are (if in motion). There are a max of 3 at any given time.
foreach (Point p in spaceInvaderController.BulletsInAIFormat())
{
if (p.Y == 0)
{
// no bullet.
data.Add(0);
data.Add(0);
}
else
{
data.Add((double)p.X / OriginalDataFrom1978.c_screenWidthPX);
data.Add((double)p.Y / OriginalDataFrom1978.c_screenHeightPX);
}
}
// Provide the AI with a 1/0 indicating alive/dead for each alien.
// We don't provide the locations of each alien, because they are all relative to the reference alien.
// We do however give it the location of the reference alien, and the direction/speed aliens are moving.
// Remember, this isn't like my Missile Command AI / Hittiles, where we have a heat sensor on the ship
// and steer missiles. This is very much getting it to come up with logic / formula to move/fire based
// on the inputs. It doesn't even care to know it is playing Space Invaders.
data.AddRange(spaceInvaderController.GetAIDataForAliens());
// location and speed of the saucer, if it exists
if (saucer is null)
{
data.Add(0); // direction -> not moving
data.Add(0); // location -> not on screen
}
else
{
data.Add(saucer.XDirection / (double)OriginalDataFrom1978.c_screenWidthPX);
data.Add(saucer.X / (double)OriginalDataFrom1978.c_screenWidthPX);
}
// give the player and indicator of whether there is a barrier in front of them.
// this is misleading, because there could be a hole in the barrier
if ((playerShip.Position.X >= 32 && playerShip.Position.X <= 32 + 21) ||
(playerShip.Position.X >= 77 && playerShip.Position.X <= 77 + 21) ||
(playerShip.Position.X >= 122 && playerShip.Position.X <= 122 + 21) ||
(playerShip.Position.X >= 167 && playerShip.Position.X <= 167 + 21))
{
data.Add(-1); // there is a barrier in front of the player
}
else
{
data.Add(1); // there is no barrier in front of the player
}
return data;
}
One question troubling me initially was how I could represent something in the game that isn’t present and ensure it is not misconstrued.
For example, giving the saucer a location of 0 could mean the saucer is on screen at X=0. How do we indicate it’s not on screen yet? In this instance, I provide 0 for direction and hope the AI copes. For invader bullets, I’ve given less clarity – providing the coordinates if a bullet is in motion else (0,0). It doesn’t appear to bother the AI.
The barrier indicator is somewhat ineffective. It indicates a barrier was/should be there (to avoid blasting it). It doesn’t tell whether there is a honking big hole large enough to rain bullets down on you. Given the AI has no concept of time, it has to learn from getting killed at that spot at that time, that the barrier was as much use as a chocolate fireguard.
Vision
I mentioned earlier that I reversed my decision to make an option for the AI to use the screen. It just felt wrong not to try.
To make it possible without requiring GPU processing libraries (offloading logic to the GPU), I had to compromise by degrading the resolution from 224×256 to 56×64 pixels – a mere 3,584 pixels down from 57,344.
For that, I wrote the method “.VideoShrunkForAI()” in “VideoDisplay.cs“, which works off the back buffer (the rendered image as an array).
It’s surprisingly easy to achieve, if we divide the screen into blocks of 4 x 4 pixels. If one or more pixel is illuminated in the box, I give a “1” to the AI else a “0”.
It’s not perfect, as the player’s shot is 1px wide, and the AI input doesn’t have the same resolution… It’s not helpful to count illuminated pixels / 16, because it gives you no directionality within the 4×4 group of pixels. One could assign bits to each of the 16, (1,2,4,8,16…) and divide by 65,536. That would give a number 0-65,536 represented 0..1 indicating which of the pixels are illuminated but I just don’t see how that helps the AI…
If you can think of a better approach, please add a comment, and I will take a look.
Here’s the AI in action using a video display input, you’ll notice in this capture I have enabled the “overlay” showing what the AI sees (“c_debugOverlayWhatAISees” = true, in “AIPlayer.cs“):
At this point it had only played around 300 games, so still quite a newbie. But more to the point, it is also using just four hidden neurons!
One can’t help but notice, how it doesn’t really appreciate having shields. They are more of a hindrance than a help. The AI is quite capable of moving out of the way of bullets after playing for a while longer.
The score / high score has not been included as part of the screen intentionally. That’s because the first time it plays the high score is 0000 as it learns. On subsequent games, it is not 0000. This has the potential to confuse the AI as pixels have changed from what it learnt. It took me a while to realise why in subsequent games the fitness appeared to decrease. It’s not that the AI can’t learn to ignore them, but that takes more training to work.
RADAR
In many of my AI applications, I employ distance sensors. I tried to avoid it, alas curiosity got the better of me!
I cannot imagine in reality that one could hack the “mothership” (are they really a thing?) and get access to internal data, whereas the radar approach is a very normal battlefield approach.
Rays are sent out in each direction and if they encounter something, it returns the distance. What is unusual this time is that I employed two radars, not one. The target radar is shield penetrating (goes thru) and detects invaders/saucers/bullets. The shield radar only detects the shields. This enables it to know there is a shield present, and whether it has a hole in it.

It’s a good job the player can only fire upwards, otherwise, this would be a repeat of my Missile Command except with invaders!
The elephant in the room is the shield, that will appear on the radar and indistinguishable from the invaders. You might be wondering whether I am colour-blind, no the bases are green, and the aliens are white. Or so you think. Not quite right…

That happens because the “colour” green/magenta is via semi-transparent coloured films stuck in front of the black/white screen. Because I’ve tried to be authentic, anything in the green region will be green, not white – bullets, shields and invaders…
To be able to differentiate I used the “alpha” channel (252 for the shields).
Performance is better for not drawing the alpha channel (except when clearing the screen to 255). That meant everywhere, I’d needed to plot the alpha…
I am no expert in radars, but I am guessing a picture of a radar screen isn’t helpful, it lacks context. Radars repeatedly scan, and from multiple frames, one can tell direction. Rather than mess around with radar frames, I have opted for something that the internal data told it – the delta X for the aliens (sign tells the AI whether they are moving left or right, and the magnitude provides the speed).
AI Output
Control-wise the original game has 3 buttons – left, right and fire, that look something like this:

I have no idea if there have been studies on the best way for AI to communicate its desires, so I’ve opted for two relatively obvious approaches:

Position: [2 outputs]
- AI provides the X coordinate on the screen where it wants the player ship placed
- AI provides an indicator of whether to “fire” or not
OR
Action: [1 output]
- AI provides an action 0-5.
- 0 = left, 1 = left + fire, 2 = fire, 3 = no move, 4 = right + fire, 5 = fire
The 1st is implemented as below. I don’t know what other AI/ML researchers/coders do, but to decide whether to fire, I went for a simple threshold approach. Whilst the AI may want to go to the other side of the screen, that would be cheating, so the MovePlayerTo(location) is in fact moving left/right 1px depending on whether the desired location is left or right of the player.
private void AIChoosesXPositionOfPlayerAndWhetherToFire(Dictionary<string, double> outputFromNeuralNetwork)
{
// output is a value between 0 and 1, so multiply by the screen width to get the desired position
int desiredPosition = (int)Math.Round(outputFromNeuralNetwork["desired-position"] * 208 /* OriginalDataFrom1978.c_screenWidthPX - 16*/ ); // where it wants to go
// clamp the value to the screen width, just to be safe
desiredPosition = desiredPosition.Clamp(0, 208 /* OriginalDataFrom1978.c_screenWidthPX - 16 */ );
gameController.MovePlayerTo(desiredPosition);
// fire if the output is greater than 0.5
double fire = outputFromNeuralNetwork["fire"];
// the only way to know intent of fire or not, is to decide what indicates "fire". In this case, it's 0.65f.
if (fire >= 0.65f) gameController.RequestPlayerShipFiresBullet();
}
public void MovePlayerTo(int desiredXPosition)
{
if (playerShip.Position.X == desiredXPosition)
{
CancelMove();
return;
}
if (playerShip.Position.X < desiredXPosition)
{
SetPlayerMoveDirectionToRight();
return;
}
if (playerShip.Position.X > desiredXPosition)
{
SetPlayerMoveDirectionToLeft();
}
}
The 2nd is nothing but a simple switch statement from the neural network output (0..1) scaled 0-5.
private void AIChoosesActionToControlPlayer(Dictionary<string, double> outputFromNeuralNetwork)
{
int action = (int)Math.Round(outputFromNeuralNetwork["action"] * 5);
// outside range, does not move or fire
if (action < 0 || action > 5) action = 2;
switch (action)
{
case 0:
gameController.SetPlayerMoveDirectionToLeft();
break;
case 1:
gameController.SetPlayerMoveDirectionToLeft();
gameController.RequestPlayerShipFiresBullet();
break;
case 2:
gameController.CancelMove(); // no move
break;
case 3:
gameController.CancelMove();
gameController.RequestPlayerShipFiresBullet();
break;
case 4:
gameController.SetPlayerMoveDirectionToRight();
gameController.RequestPlayerShipFiresBullet();
break;
case 5:
gameController.SetPlayerMoveDirectionToRight();
break;
}
}
Both approaches work, but the calculation it performs is clearly different.
In the first, the AI equation must derive a position, although is not aware that if it’s clamped to move 1px left/right. The fire is effectively an independent circuit. With the 2nd it has to somehow combine both values into a single output.
Why did I not map buttons to outputs, e.g. 3 outputs? Good question. My main concern is the left contradicting right and the benefit of doing so. I know humans could bash both buttons, but a 3 output option feels like a less efficient version of option #1.
If anyone out there wants to try a 3-button output, please feel free to fork the code and post the results in the comments.
The next section looks at the neural network.