Summary/challenges
I set out to –
- make an AI that wins at 1978 Space Invaders, and it does!
- prove that you can achieve a lot with very little. In total 8 levels require training, with approx 4 neurons each (some use 3), that’s a total of 32 hidden neurons to win the game!
When I saw the Atari 2600 Space Invader’s top scores, I wanted to see how well I faired. Of course, it’s not an exact comparison – the games are different. But I see no reason mine is invalidated.
It’s easier to solve problems when you break down problems into manageable chunks. I also did it “my” way. Whilst I don’t recommend ignoring proven approaches, the world was not built without innovation and inspiration. Don’t be afraid to try something new.
If you can bring oodles of top-end GPUs, and fast CPUs to bear it probably doesn’t seem so painful to train, or maybe it does for reinforcement learning. I don’t know. I worry however about wasting my time, so I was often more likely to kill a training session tweak something and try again. The problem with that however is being sure if the tweak made the difference…
The biggest “unknown” results from using a cryptographic random number generator for all decisions (mutation) and setup/modifications to weights, and biases. Mutation very much depends on randomness. Run it twice, you end up with a different AI each time.
Depending on your configuration goal (one network, all levels vs. one level) it can run for a couple of hours playing games, and suddenly it comes across an AI that beats the existing score; sometimes a little other times by a lot. The randomness makes it very hard to compare different runs.
If you want one neural network that provides consistent gameplay for all levels, that will take much longer than the way I achieved it. As usual, there are easier ways to achieve the same outcome in less time.
This has been an enjoyable but time-consuming journey and a lot of iterative-driven engineering behind it. When I set out, I had no intention of building the game. Neither did I dream of all the features, of which there are plenty. But in the end, it was worth it.
I am left with many unanswered questions.
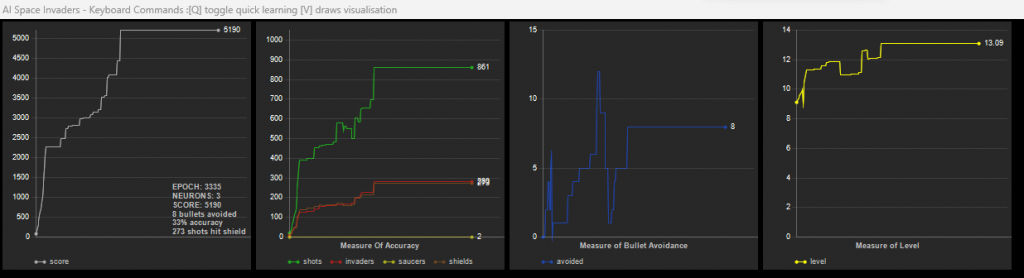
It works with RADAR and INTERNAL. Below is a THREE-neuron hidden network using “internal data” scoring 5190 going from level 9 to 13. That’s 4 completed levels using internal data alone. Let me say that again “4 levels completed using just 3 hidden neurons“. No reinforcement learning or other clever stuff. If you look closely it only scored 5190 – a rookie mistake; I forgot to start level 9 with the correct score – meaning the first levels were done with a slow firing rate. But still, 3 neurons I think is pretty impressive.
I have yet to leave it running for any length of time using the video screen, although I do know it can complete levels. It’s slower (because of the 3,500 inputs resulting in lots of connections and thus quite an overhead). Ultimately successful or not is tricky to know. Could it fail to achieve greatness because the downscaling of pixels is too inaccurate? Might it improve if I halved rather than quartered?
Maybe I will check that out in due course.
I’ve tried various activation functions, and somehow it worked regardless of the one I picked. This is a little disconcerting and I genuinely don’t know which is best.
What is the optimal number of neurons? What types work best?
What fitness scoring multipliers provide the quickest learning?
If you leave it long enough, will a small number of neurons eventually complete all the levels?
My takeaway from this is how easily one can shape an answer that satisfies multiple datasets and use it to achieve a task. It is cool how it solves the problem without future predictions of aliens or bullets. But it isn’t amazing – I expected it to work from the outset.
Teaching an AI to play would be far more efficient than evolution. In the future after ChatGPT, I could imagine using instructions to refine the AI gameplay. Start off by giving it access to the display, then point at the sprites, and explain the game. GPT4 has made inroads into human reasoning, so there is definitely potential… Giving humans strategy guidelines enables them to play well, but the practice is very important. I am not convinced an AI can become good at a game without actually playing it.
Beating Space Invaders should be relatively trivial to a human, yet even with practice, most will never score 10,000 points. With each game they will improve their strategy, what holds them back is their hand-eye coordination. When you get down to that last pesky invader, timing is critical. Humans often crumble under pressure usually when panic sets in. Some people are naturally good, and others no matter how much practice will ever be a top player…
My AI mp4 video demonstrates the basic approach for the earlier levels. Kill a few, then hide behind a shield. Make a hole in it, and keep blasting them. What is important on all levels is to reduce the edge columns as early as possible. A wide row of aliens will go downwards sooner. By pruning the edges, there are more frames available in which to pick off the rest. The hide-behind works well until level 7 onwards when the invaders start off really low. It’s vital to get rid of the lower ones, and edge ones asap. Hiding behind a shield slows that down.
There is a bug in the 8080 code (thanks Topher for explaining) where if the last alien is the top left, shooting the shield will kill it (when in the region of the shield); I did not implement that bug. Leveraging the wall of death (invaders are in the row above the player, do not shoot), and picking them off is a tactic often used – except leaving it that late and getting the timing wrong is the end of your game.
For more tactics, please see the play guide that I shared at the start.
I hope you found this interesting, and enjoy experimenting with my code. If so, please leave a comment!