Pong is a table tennis-themed arcade sports video game, featuring simple two-dimensional graphics, manufactured by Atari and originally released in 1972.
Before we start
To shorten this post, I’ve put the Pong gameplay details and tactics on a separate page. The AI context may make more sense after reading, but I leave that up to you.
An article came out a few days before I posted this publicly – “Brain cells in a lab dish “exhibit sentience” by learning to play Pong“. What next? Will they write blog posts?
Starting with a simple goal
Let’s initially set our goal low to test something but not as low as using xbat = xball assignment, cheating is not permitted on my blog!
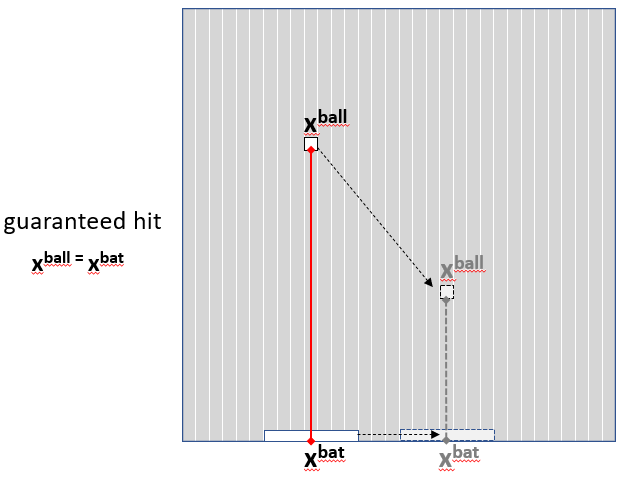
We can provide the neural network with a playing field and an opportunity to hit a ball.
Neural Network Attempt 2.0
The code for this is on GitHub.
No, that’s not a typo, attempt 1 isn’t going to be covered here. It worked, well sort of.
In Pong 1.0, I used genetic mutation (trial and error). Training yielded a rather disappointing player. It struggled to configure weights and biases to produce the correct response consistently. It comprised 16 neural networks, 16 virtual tennis pitches and wasted hours of coding.
For Pong 2.0, initially let’s stick to our first goal, and here it is in motion:
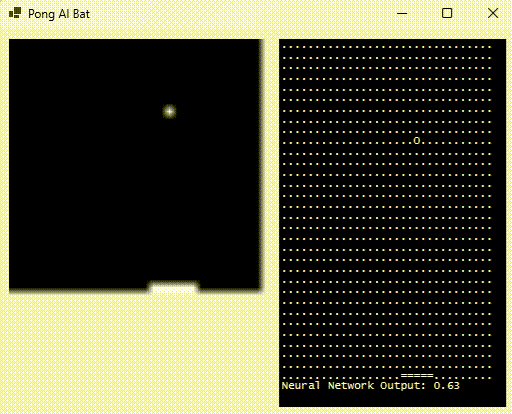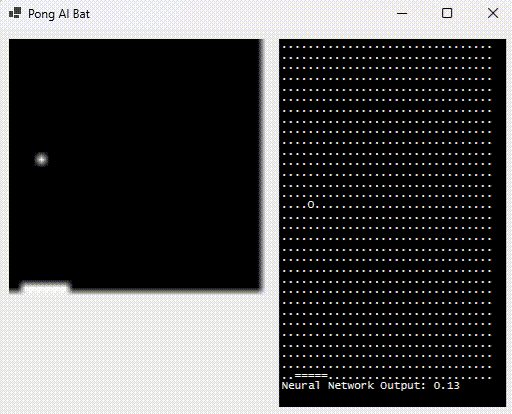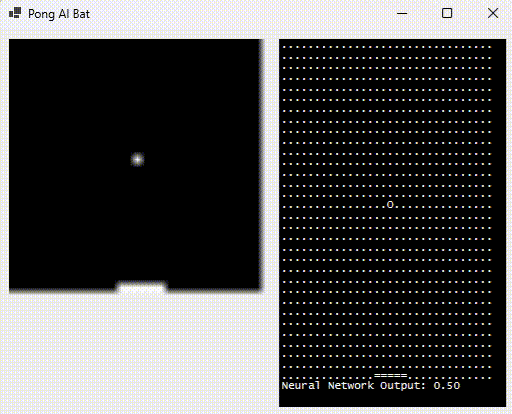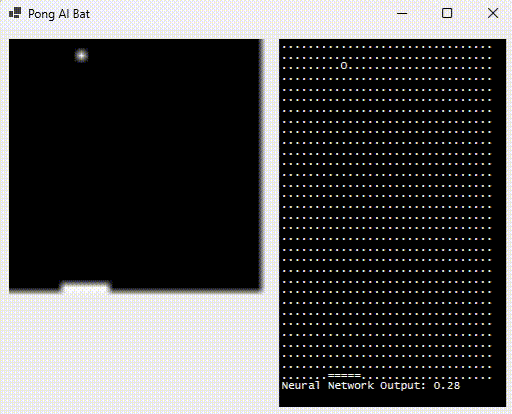
The right-hand side shows what the neural network sees (by rendering the inputs as “.” or “o” based on 0/1) as well as the bat position (output, proportional to the width of the playing area). The green flash indicates that it hit the ball.
What’s the relevance of “sees“? Good question, glad you asked. Humans don’t receive the (x,y) cartesian coordinate of the ball when they play the game. They “see” the pixels and their brain decides what their fingers need to do; subsequent feedback adjusting for error.
Achieving this task is another one of those “linear” things; I know, predictable me, albeit this time requiring no sensors – progress?
For each position the ball is in (32×32 pixel playing field), we backpropagate the “desired position of the bat”. The training is that simple albeit doing so repeatedly until backpropagation sets the bias/weights accurately.
I hate the use of backpropagation.
Backpropagation doesn’t feel like learning but “configured”. I am not against “feedback” resulting in “learning”/”adapting behaviour”, I am just not sold on back-propagation. Humans learn, but not in that way. I don’t think humans “configure” themselves, I would argue that is something people are not very good at. Backpropagation leads to rigid learning. Ok, maybe I don’t quite hate it enough never to use it ever again, however, I don’t like it.
Neural Network: Perceptron, backpropagation, activation function TANH
- input: 1024 (pixels representing, white for the ball, black background)
- hidden: 0, this is input->output
- output: 1 (desired location of bat / 32)
// video display is 32px * 32px
for (int ballX = 0; ballX < 32; ballX++)
{
if (!trainingData.ContainsKey(ballX)) trainingData.Add(ballX, new List<double[]>());
for (int ballY = 0; ballY < 32; ballY++)
{
double[] pixels = new double[1024]; // 32px * 32px = 1024.
pixels[ballX + ballY * 32] = 1; // where the ball is.
trainingData[ballX].Add(pixels);
}
}
It’s not that we cheated with the ball, it is reading a Bitmap containing the ball when running and deciding where to move the bat. It’s just for training, writing bitmaps and reading them when you have the answer in an array would be stupidly inefficient.
The bat .Move() is implemented like this:
/// <summary>
/// Moves the bat to wherever the AI chooses.
/// </summary>
internal void Move()
{
result = AIviewFromAboveAndDecideResponse32x32pixels();
// AI decides WHERE it wants the bat to be positioned (expressed as fraction of 32, 0..1, so we multiply by 32)
desiredPositionOfBatX = Math.Round(result[0] * 32);
// attempt to move towards the desired bat position, at max 3px per move
CenterPositionOfBat = Clamp(desiredPositionOfBatX, CenterPositionOfBat - 3, CenterPositionOfBat + 3);
// ensure the bat doesn't go past the edges
if (LeftPositionOfBat < 0) CenterPositionOfBat = c_widthOfBatInPX / 2;
if (RightPositionOfBat > 31) CenterPositionOfBat = 31 - c_widthOfBatInPX / 2;
}
/// <summary>
/// Returns ALL the pixels as a "double" array. The element containing a 1 has the ball.
/// </summary>
/// <returns></returns>
private double[] AIviewFromAboveAndDecideResponse32x32pixels()
{
pixels = new double[1024];
// convert 4 bytes per pixel to 1. (ARGB). Pixels are 255 R, 255 G, 255 B, 255 Alpha. We don't need to check all.
for (int i = 0; i < pixels.Length; i++)
{
pixels[i] = Pong.s_rgbValuesDisplay[i * Pong.s_bytesPerPixelDisplay] != 0 ? 1 : 0; // 1 = ball (white pixel), 0 = no pixel.
}
return NeuralNetwork.s_networks[Id].FeedForward(pixels); // [0] => new position for the bat. X = 0..31 encoded as X/32.
}
The only part of it worthy of mentioning above is the “Clamp”. Knowing where you want to position the bat, isn’t the same thing as “moving” to that position. The clamp limits the amount the bat can move in one frame, otherwise, the bat would always instantly appear where the ball is. That would be cheating and not realistic enough.
Before someone says “Dave, you realise that’s super inefficient – right?”, I’ll describe an optimisation.
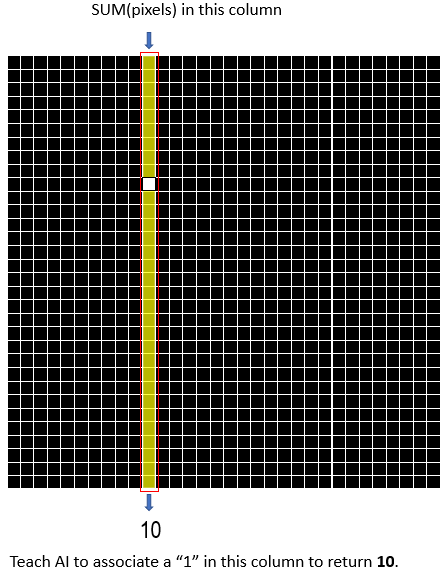
Instead of training on 1024 pixels, you could reduce by creating an array[32] that has a “1” if ANY row in that column has a 1.
<== columns ==>
1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 => 0
…
0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 => 4
…
0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 => 10
…
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1 => 31
We “teach” it that a “1” in a particular column must return the index of that column like a .IndexOf(). It’s conceptually no different to what the neural network learnt to do from the 1024 bytes, just less of them,
It feels like this is getting closer to cheating with xbat = xball, but it’s no different to all those “kernels” stuck in the middle of neural networks that perform “edge detection” etc.
This was a simple foray into the relationship between seeing and reacting. Whilst alone it won’t win any awards apart from the “why bother?” category, this is the beginning of Pong, not the end.
I hope to post several articles on this, not because Pong is addictive to play but so you can come on the AI journey if you want to…
Click here for Part 2, where we do it a smarter way and create one that learns as it plays.