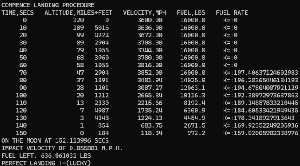
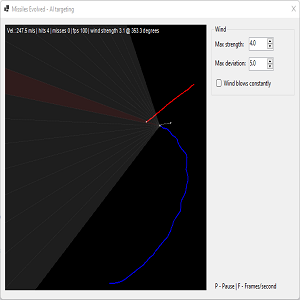
What is ADAM?
Here’s a good explanation courtesy of Bing:
Imagine you’re learning to make the perfect cup of tea. Each time you make a cup, you might tweak the amount of tea leaves, water temperature, or steeping time to get it just right. You use your past experiences (whether the tea was too strong or too weak) to make these adjustments.
In the world of machine learning, we’re also trying to make something just right: a model that makes accurate predictions. The Adam optimizer is like your method for making better tea each time.
Here are the key components:
- Weights and Biases: Think of these as the recipe ingredients. Weights determine how important each ingredient (or feature) is, and biases are like little adjustments to the recipe to make it taste better.
- Learning Rate: This is how big of a change you make to your recipe each time. Too big, and you might overshoot the perfect cup of tea; too small, and it’ll take forever to get it right.
- Gradient: This is like your taste test feedback. It tells you if your current cup of tea is too strong or too weak, guiding you on how to adjust your weights and biases.
The Adam optimizer combines two other methods:
- Momentum (which smooths out the changes based on past taste tests) and
- Adaptive Learning Rates (which adjusts how big the changes are based on how confident you are in your current recipe).
So, in short, the Adam optimizer helps the model learn faster and more effectively by tweaking the recipe (weights and biases) based on past experiences (gradients), using smarter adjustments (momentum and adaptive learning rates).