Adjusting the Learning Rate
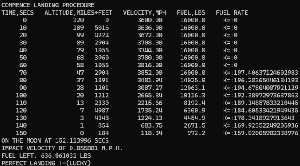
Training a neural network is performed by adjusting weights and biases based on the error. We do so by multiplying them with what’s known as a “learning rate”. Previously, I’ve picked a value and left it constant. The question I am attempting to answer is when there are some alternatives, which works best?
By multiplying by a larger learning rate, we move weights and biases closer to their optimum quicker (by taking bigger bites off the error). However, it can lead to overshooting and thus oscillation (it swings back and forth around the desired value). Reducing it as we start to converge makes sense.
Using a learning rate that is too small results in it taking forever to converge.
If slowly reducing the learning rate was all that was required, there wouldn’t be different alternatives. Sometimes increasing the value helps move it out of the valley it has become stuck in and closer to the optimum.
I’ve implemented the following learning rates (using GitHub Copilot) and if my code is incorrect, the fault is mine for either being dumb enough to trust generative AI or even stupider incorrectly modifying it.
Again, I’ve leveraged Bing to explain each optimisation.
Step Decay
Imagine you’re climbing a staircase. Every few steps, you stop to catch your breath, which slows down your pace for a bit, but helps you in the long run.
In the context of machine learning, Step Decay means reducing the learning rate (how big a step the model takes) at fixed intervals (like every few steps). This helps the model make more precise adjustments as it gets closer to the optimal solution.
Exponential Decay
Think of this as gently slowing down a car. Initially, you’re going fast, but you gradually slow down over time.
Exponential Decay reduces the learning rate by multiplying it by a factor (less than 1) after every epoch (one full pass through the training data). This means the learning rate decreases exponentially, helping the model make finer and finer adjustments as it learns.
Reduce On Plateau
This is like adjusting your efforts based on progress. Imagine you’re trying to reach a goal weight. If you hit a plateau where your weight doesn’t change despite your efforts, you might change your diet or exercise routine.
In machine learning, Reduce On Plateau means reducing the learning rate if the model’s performance (accuracy or loss) stops improving for a certain number of epochs. This helps the model make more effective adjustments when it gets stuck.
Cosine Annealing Cyclical Learning Rate
Imagine you’re cycling up and down hills. You need to adjust your pedalling speed to handle the changing terrain.
Cosine Annealing Cyclical Learning Rate adjusts the learning rate in a periodic manner, following a cosine function. This means the learning rate starts high, decreases to a minimum, then increases again, and repeats. This cyclical pattern can help the model escape local minima (suboptimal solutions) and find a better overall solution.