Conclusion
Today’s winner (and hopefully every time) is Cosine Annealing, with ADAM based on a sample size of 1000 random networks, stopping at 0.8F or 5000 epochs.
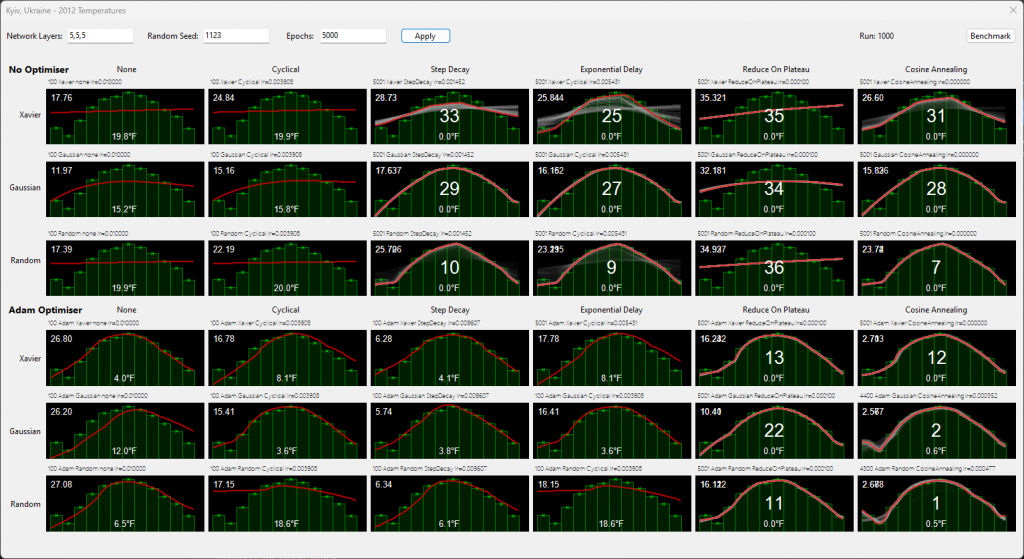
When I started the journey, it was a few random runs. For statistical significance, sample size is important. I modified the app to run repeatedly with different seeds.
Whilst 1000 runs is a tiny sample, it should be statistically valid because it demonstrated no matter what the network started with (remember all are as identical as possible for a seed), Cosine Annealing + ADAM matched the curve extremely consistently.
ADAM wasn’t a magic bullet.
Without an algorithm adjusting the learning rate, it curiously faired badly. Whilst one might assume it’s because 0.01 is a high learning rate, I’d like to point out that the same network without ADAM coped better with the same learning rate.
With a smaller network 3-3-3, the same result:
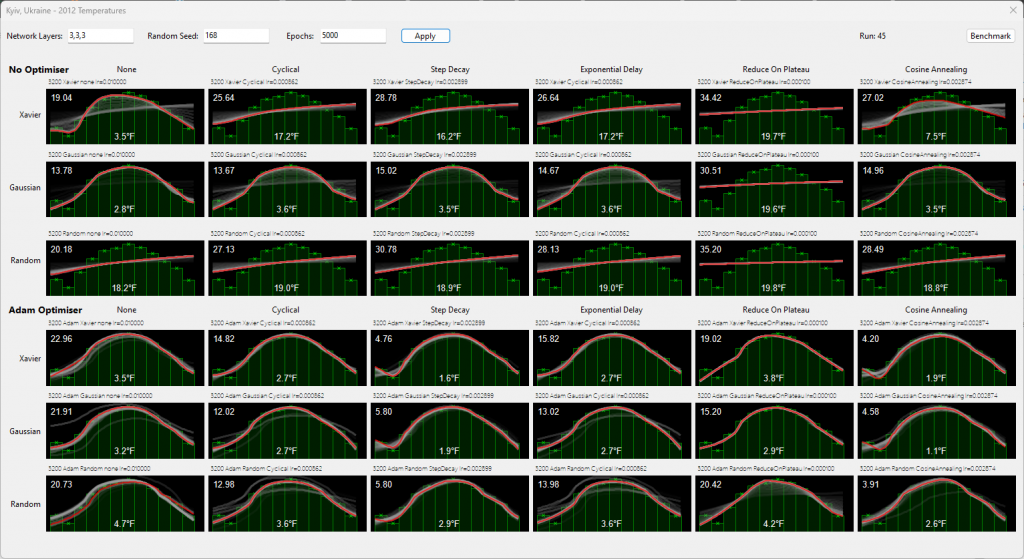
Is there something that makes this data favour Cosine Annealing? Good question. Whilst I cannot say for sure, I found it worked best for my next blog post (AI basketball). Coincidence?
For now, my default will be ADAM + Cosine Annealing.
The 2nd best choice is ADAM + StepDecay.
If you want to try it for yourself, the source code is on GitHub. If you wish to voice an opinion regarding it, please add a comment.