Drilling Into the Components
(or: the part where I pretend this was all intentional)
Caching
Let’s start with the cache — not the Anthropic “cache” that politely asks the model to remember things, but a proper, grown‑up, deterministic cache. The kind of cache you need if you ever want to make money from this venture and avoid burning 6000 tokens every time someone asks, “Who did Dave marry?”
The idea came from the PII‑redaction trick I mentioned in an earlier post: abstract the user’s question so the system can recognise when two questions are secretly the same. If the system has already planned for:
“Who did Dave marry?”
then it can reuse that plan for:
“Who did Mary marry?”
Same structure, different poor soul being interrogated.
Of course, humans are inconveniently creative. Someone will ask:
“Who is Dave’s spouse?”
Same meaning, different phrasing. So the cache grows… and grows… and grows… until one day it doesn’t, because you’ve finally seen every possible way a human can ask about marriage.
To do this abstraction properly — across languages — I use Haiku. Yes, there are non‑LLM libraries that claim to do this, but they tend to assume English rules apply everywhere. Spoiler: they don’t. Proper nouns don’t always start with capitals. Word order changes. Some languages treat numbers like decorative suggestions.
So the system rewrites:
“Who did Dave marry?” into “who did [P_1] marry”
and:
“Which of Karen’s children were born after 1944?” into “which of [P_1] children were born after [N_1]”
A tiny token cost to abstract, a quick DB lookup, and worst case: you still plan and then save the plan. Early on, this costs more than it saves. But soon, it becomes a money‑saving machine — the kind of machine investors love.
Plan Agent
This has never been a RAG problem. It’s not about retrieving documents; it’s about understanding what the user wants to do. That’s where the operator‑algebra approach comes in.
What does that mean in practice?
It means the model expresses intent at a data‑level:
- “Look up the person Dave and assign to v1.”
- “Fetch the first spouse of v1 and assign to v2.”
- “Return v2.”
All while juggling people, events, locations, and the occasional genealogical curveball.
I can’t go into the full details — this is the part of the system where the magic sauce lives, and I’m not giving away the recipe. But suffice it to say: it works, and it’s the reason the whole thing doesn’t collapse into a puddle of hallucinated cousins.
Parse → Compile → Execute
The planner produces algebra. Sometimes beautiful algebra. Sometimes… not. So there’s a repair loop: if the plan is invalid, it gets sent back to the model with a stern note explaining what it did wrong. Sonnet gets another go. Sometimes two.
Once the plan is valid, the pipeline moves on.
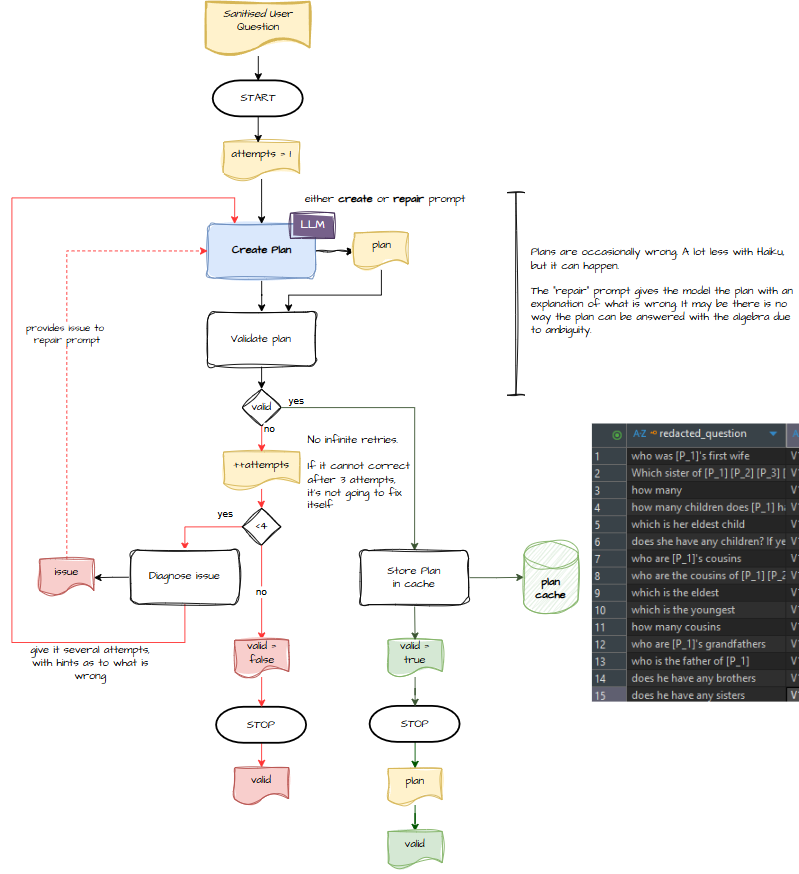
For the first turn, the user can’t refer to “he”, “she”, or “they” — there’s no context yet. So after parsing comes compilation, which turns the graph into something executable.
Execution itself is simple: walk the plan steps in order, assign data to variables, return the result. No hallucination, no improvisation. Just deterministic operations over people, events, and counties.
Underneath all this is my GEDCOM parser, with a thin tool‑layer the executor can call to perform operations. It’s not glamorous, but it works.
Answering
Getting the model to answer was its own adventure. I tried JSON. Everyone says JSON is the way. JSON is clean. JSON is structured. JSON is the future.
JSON was terrible.
For simple data, it’s fine. But genealogy is rarely simple. So instead, I generate facts — small declarative statements the system derives as it walks the data. The answer agent then turns those facts into prose, in the user’s language, without inventing new relatives along the way.
Compilers & Discourse
Here’s where things get spicy.
User: “Who did Dave marry?” System: “Mary.”
User: “What is her sister’s name?”
Your brain instantly rewrites that as: “What is Mary’s sister’s name?”
LLMs, however, need help. They don’t magically know who “her” refers to. So the system performs two steps:
- Referent resolution — figure out who “her”, “them”, “they”, etc. refer to.
- Subject resolution — rewrite the question so the planner can handle it.
This sounds simple. It is not simple. Add multilingual support, and it becomes a small circle of hell.
Another lesson learned: scope your MVP properly.
I assumed, “I’m using an LLM, therefore multilingual is basically free.” It was not free. It was the opposite of free. With hindsight, I should have launched in English first (a perfectly large market), earned revenue, then expanded. Instead, I spent months in the swamp of “unknown unknowns”.
The compiler knows what each operator expects and rewrites the plan accordingly. It injects discourse information so the executor can resolve pronouns deterministically.
Referents originally lived inside an LLM prompt. Then Bing Copilot helped me turn it into a multilingual deterministic algorithm. It took many attempts and a lot of edge cases — but once I had a large corpus to test against, the system finally stabilised.
