(in which I return after three months, older, wiser, and slightly more suspicious of Qwen)
This follows on from: Generative AI for Genealogy – Part XVIII
It’s been more than three months since the last instalment of this saga, which in startup time is roughly equivalent to a decade, three pivots, and at least one existential crisis. Don’t worry — the genealogy project didn’t die. It merely went into one of those quiet “I’m fine, everything’s fine” background modes while I wrestled it into version 5.
Each version nudged the needle forward… before politely handing me a fresh set of “new” flaws to ruin my weekend. It’s the kind of iterative progress where you celebrate a breakthrough on Tuesday, and by Thursday, you’re staring at the ceiling, wondering whether the entire field of AI is an elaborate prank.
If you take only one piece of advice from this post, let it be this: use a current model. Haiku. Sonnet. Something with a pulse. I, however, spent months trying to make Qwen2.5 behave — powered by determination, misplaced optimism, and the kind of wishful thinking normally reserved for lottery tickets.
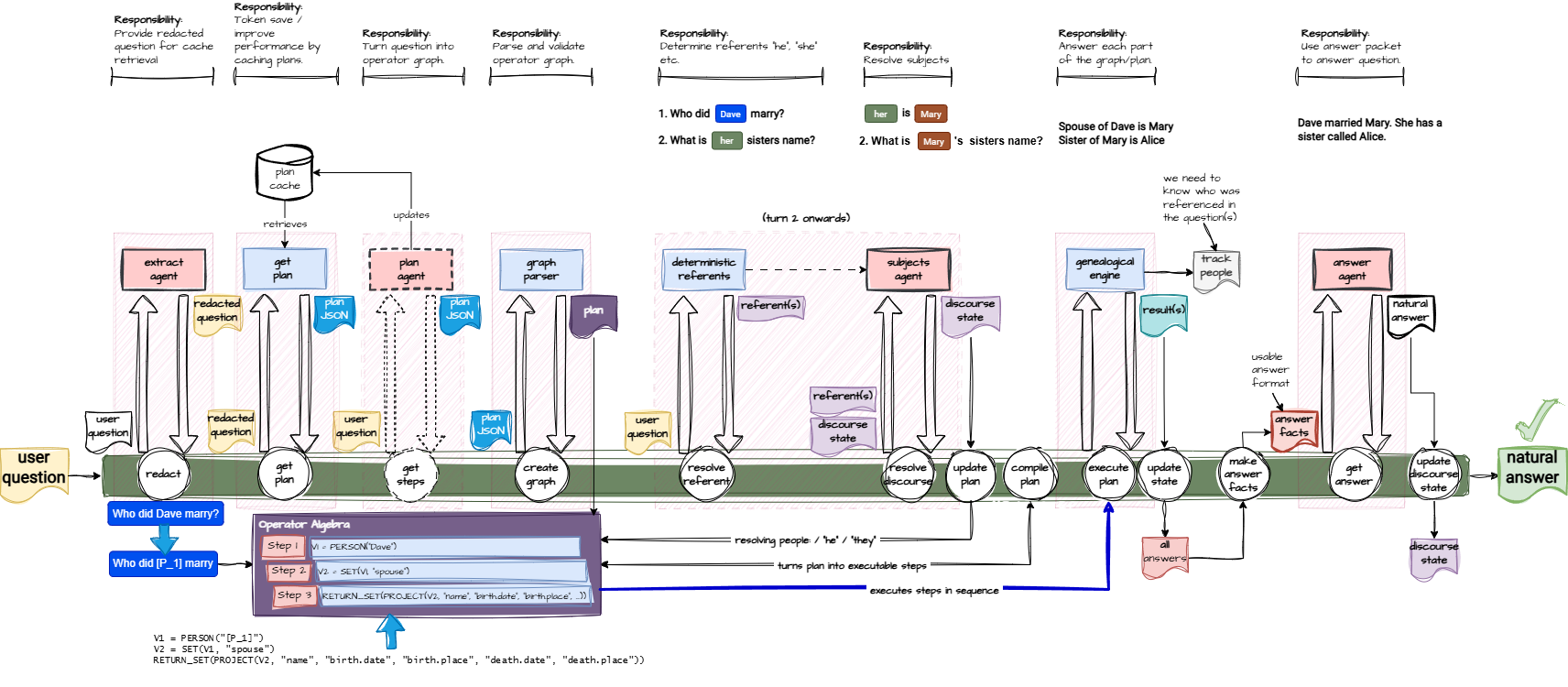
The core problem? I simply couldn’t trust the model to navigate people and relationships reliably. And in genealogy, “mostly correct” is not a vibe. Throwing more rules at it didn’t help. Adding examples didn’t help. Threatening it didn’t help. Eventually, I accepted the truth: I needed a new approach. That approach became the planner‑output operator algebra — a phrase that sounds like it should require a chalkboard and a pipe.
But before I reached that epiphany, I tried… things. One experiment involved an agent that planned, looped, replanned, and looped again until it produced a final answer. It was like a tiny genealogy‑themed OpenClaw: adorable, chaotic, and absolutely not production‑ready.
Then came the multi‑turn nightmare.
Anyone who’s done LLM training knows the rule: every turn must include the entire conversation history in [{ "user": "...", "assistant": "..." }] format. Genealogy, however, is verbose. After a few turns, the model starts to lose the plot, forgets who is related to whom, and begins hallucinating uncles like it’s on commission. The only way out is to venture into the linguistic underworld of referents and subject resolution — the place where pronouns go to die.
So what does it take to make this work? About 6000 tokens just to plan, a combination of Haiku and Sonnet, and a willingness to embrace complexity like an old friend who always shows up uninvited.
If you remember the earlier posts, the architecture used to be simple:
UI → Plan Agent → Fetch Data → Answer Agent → UI
A clean, elegant pipeline.
That has now evolved into something more like:
Extract → Cache → Plan → Parse → Referents → Subject Resolution → (several other steps I’m too embarrassed to list) → Answer
Imagine the original diagram, but now with more arrows, more boxes, and the faint smell of over‑engineering.